
Runtime Fabric has consolidated as the most flexible deployment option for the Mule runtimes. Anypoint Runtime Fabric can be installed in your on-premises data center or cloud-hosted environment (Azure, AWS). This type of deployment is similar to that of CloudHub in that it offers high availability and has zero-downtime for data centers.
To provide these capabilities, Anypoint Runtime Fabric must be installed following a set of minimum system requirements and a specific architecture. In this post, we’ll look at the server’s architecture, what type of servers we need, and how many.
Runtime Fabric supports configurations
But first things first, what type of role servers do we have in a Runtime Fabric architecture? There are two types of server/nodes:
- Controller nodes: They are responsible for managing the cluster, running the orchestration services, and load balancing.
- Worker nodes: These are the nodes responsible for running Mule applications.
Now that you know the type of nodes in our architecture, let’s learn how to combine them. Not every possible combination of nodes will be valid, we can’t just put any number of controllers and workers together. There’s a minimum of system requirements depending on the type of environment we’re creating. There are two types of supported configurations:
- Development configuration:
- Minimum requirements:
- 1 controller node
- 2 worker nodes
- Minimum requirements:
- Production configuration:
- Minimum requirements:
- 3 Controller Nodes
- 3 Worker Nodes
- Minimum requirements:
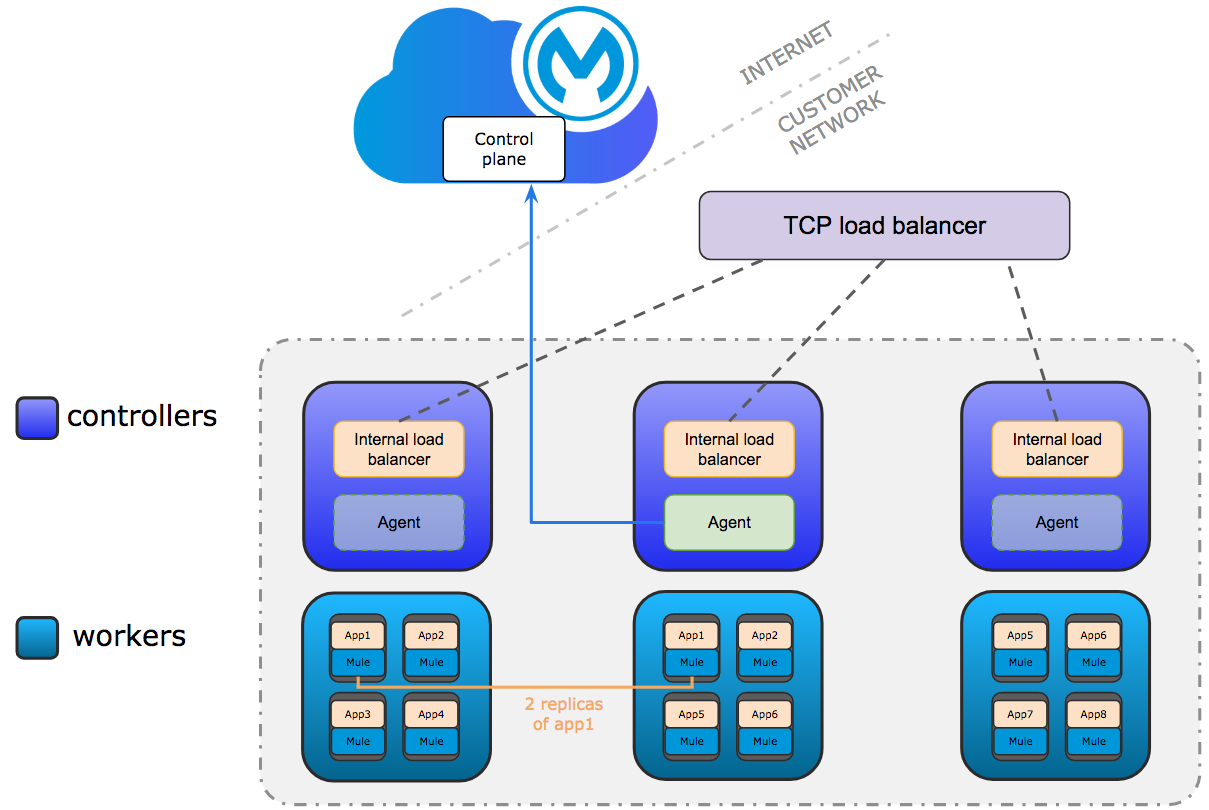
In terms of numbers, it’s also important to note that the maximum number of worker nodes is 16 and the maximum number of controller nodes is 5. The controllers, in addition, can be only in an odd number.
Let’s focus now on the controllers. As stated above, the minimum of controllers is one for dev and three for production. The maximum is five and it can only be an odd number. That leaves us with precise numbers:
- For development, we can use one, three, or five controller nodes.
- For production, we can only use three or five controller nodes.
Why are these numbers so specific? The answer resides in the underlying technology.
Anypoint Runtime Fabric’s underlying technology
Runtime Fabric uses Kubernetes as the container orchestration technology and an instance of Etcd to maintain and persist the cluster state. This Etcd database is a distributed and reliable key-value pair store where Runtime Fabric saves the cluster’s defined configuration, its current state and the metadata associated. Etcd runs in all the controller nodes of the cluster and is responsible for ensuring there are no conflicts between the controllers and that every copy of the same data is consistent across the different controller nodes.
All the Runtime Fabric cluster information is stored in files, typically JSON or YAML. The goal of Etcd is to guarantee that this information is always the same, no matter from which node we’re accessing the cluster information.
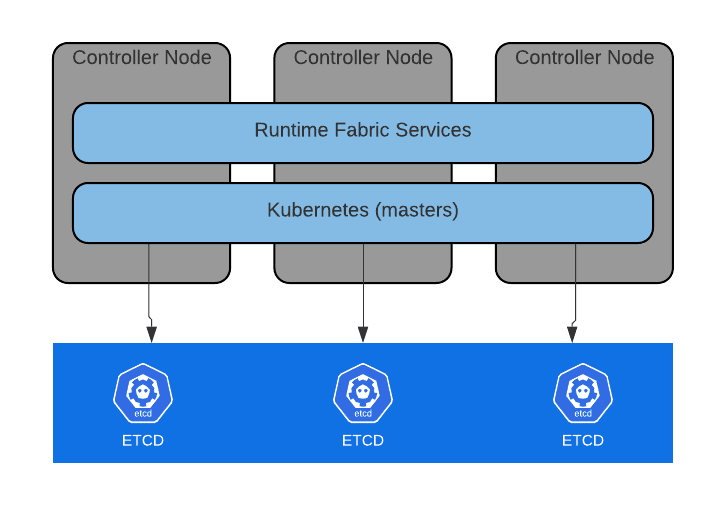
The controllers will do one of two types of operations into this Etcd store: reads and writes.
With reads it’s easy, since the same copy is available in all instances you can read from any node.
Writing is more complex. What if two write requests get to two different Etcd nodes? Which one goes through? In an Etcd cluster, not all the nodes process the write requests — only one of the nodes, known as the leader, is able to process a request to write. Internally, the nodes in an Etcd cluster elect a leader amongst them, one node becomes the leader and the rest become followers. The process of electing a leader in the cluster is out of the scope of this post, we’ll just mention that it’s based on the RAFT algorithm.
This way — when a write request is received by any controller node — the node does not process it. Instead, it forwards that request to the leader. It will be the leader writing to the database and afterwards makes sure that all the followers receive a copy of the data. The write is considered complete when the leader receives confirmation from the majority of the nodes in the cluster.
This concept of majority is the key in the functioning of Etcd and this is exactly what determines the number of controller nodes in a Runtime Fabric cluster. Majority is what we call quorum in a cluster terminology, it’s the minimum number of controller nodes that must be available for the cluster to function properly or make a successful write to its database.
In a N nodes cluster, quorum = N/2 + 1. Let’s put some numbers to this formula and see our options in a Runtime Fabric architecture:
- When we have one controller node, as in our minimum development configuration, if the controller goes down, the system goes down.
- If we’ve got 2 controllers, Quorum = 2/2 + 1 = 2. This means that if a controller goes down, the number of available controllers would be 1 and the Quorum 2. In this case, there would not be a quorum and the write requests would not be processed. So, even if you might think 2 controllers would give you better availability over 1 node, there’s no value in having 2 controller nodes.
- That’s why the minimum number of controller nodes for high availability in our minimum production configuration is 3. With 3 controllers, quorum = 3/2 + 1 = 2, and now we can afford having one controller unavailable. In that scenario, the number of controllers available would be 2, as well as the quorum. Our cluster would keep on working with one failure.
- Same logic applies for 4 controllers. With 4 controllers, quorum is 3, so if we lose one controller the cluster would keep on working. But if we lose another one, the number of available controllers would become 2 and Quorum 3. In other words, there’s no benefit in having 4 controllers over 3, we’ll have the same fault tolerance.
- For that reason, if we want to provide more fault tolerance to our minimum configuration we will need a number of 5 controller nodes.
- Five is the maximum number of recommended controllers for Runtime Fabric. More controllers are not really necessary to manage an environment of maximum 16 worker nodes.
Here below is a summary of the different values of controller nodes, their quorum value and the associated fault tolerance represented as the maximum number of failures.
| CONTROLLER NODES | QUORUM | FAULT TOLERANCE |
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
And now your turn! How many servers are you going to include in your Runtime Fabric architecture? Check out our webinar to learn more about how to use Anypoint Runtime Fabric.



