
This post was written by one of the stars in our developer community, Manik Magar
Mule 4 beta is already out. One of the major change in Mule 4 is making DataWeave a default expression language over Mule 3’s default Mule Expression Language (MEL). The XML namespace of DataWeave is moved from dw to ee (core), and the DataWeave version has changed from 1.0 to 2.0 in Mule 4.
Apart from syntax changes, there are many new features in DataWeave 2.0. In a series of two blog posts, I will focus on the syntax changes in DataWeave 2.0 and compare them to 1.0.
In this blog post, I will specifically discuss header changes in DataWeave (section 1) as well as iterative function changes within the body (section 2). In my next blog post, I will dive deeper into DataWeave body changes by discussing operator changes as well as other differences.
| Changes covered in this post may not be the list of all syntax changes and there may be more changes. |
Now let’s get started, a DataWeave script file can be divided into two sections:
- Header that defines directives
- Body that defines the output
1. DataWeave Header Changes
The DataWeave version has changed from 1.0 to 2.0. Along with that, the list below summarizes changes to the header sections of DataWeave:
- dw version changed from
%dw 1.0to%dw 2.0 - All directives in DataWeave 1.0 must start with
%. This is no longer needed in 2.0 (except for%dwdeclaration). - Custom functions in DataWeave 1.0 are defined with
functiondirective. In DataWeave 2.0, it has been changed tofun. Also, the function body and function signature must separate by=instead of a space.
| In both dataweave versions, you can define custom functions with either var or function(/fun) directives. |
In my honest opinion, all these changes may be trivial but they are good. The removal of %, saves you some characters and makes the header section look more like regular code instead of directives.
The two code listings below show the same script written in both versions:
%dw 1.0
%output application/json
%var user = {"firstName": "Manik", "lastName" : "Magar"}
%var foo = "bar"
%input payload application/json
%function getName(data) (data.firstName ++ ' ' ++ data.lastName)
%var toFullname = (data) -> (data.firstName ++ ' ' ++ data.lastName)
---
{
"foo" : foo,
"getName" : getName(user),
"toFullname" : toFullname(user)
}
%dw 2.0
output application/json
input payload application/json
var user = {"firstName": "Manik", "lastName" : "Magar"}
var foo = "bar"
fun getName(data) = (data.firstName ++ ' ' ++ data.lastName)
var toFullname = (data) -> (data.firstName ++ ' ' ++ data.lastName)
---
{
"foo" : foo,
"getName" : getName(user),
"toFullname" : toFullname(user)
}
{
"foo": "bar",
"getName": "Manik Magar",
"toFullname": "Manik Magar"
}
2. DataWeave Body Changes
DataWeave script’s body section is where you write all your transformation logic that defines output structure. Some interesting changes have happened to the body section of the script as well. Let’s look at those changes.
| Below grouping is not an official grouping by MuleSoft but just something I came up with. Makes it easy to write and follow :). |
2.1 Iterative Functions
You guessed it right! These are the functions that allow you to iterate and operate on a collection of objects or a single object. This can include functions like map,mapObject, filter, pluck, groupBy, etc. Some interesting changes have been made in DataWeave 2.0 for these functions.
2.1.1 Automatic Coercion from Object to Array
DataWeave 1.0 allowed automatic coercion of object to array. What that means, is in DataWeave 1.0, the map operator which allows you to iterate over array or collection of objects, was also working if the input was an object.
Consider the DataWeave 1.0 script below, where we expected to receive a list of users to map. For some reason, at runtime we received a single user object instead of the collection of users. Why? Because bugs are everywhere!.
| Our script should have either failed or generated single user object, but it generates two user objects with some really incorrect data. |
%dw 1.0
%output application/json
%var users = {"firstName": "Manik", "lastName": "Magar"}
---
users map {
"firstName": $.firstName,
"lastName": $.lastName
}
Listing:2.1.1.B – The Output
[
{
"firstName": "Manik",
"lastName": null
},
{
"firstName": null,
"lastName": "Magar"
}
]
Because DataWeave 1.0 treated every property (key-value pair) of an object as a single object and then our input object to be a collection of those objects, like the array in the listing below. Now, if you provide this as an input to map, you are going to get two objects with some null fields.
But was that the expected output from original script? Off course, Not.
[
{
"firstName": "Manik"
},
{
"lastName": "Magar"
}
]
DataWeave 2.0 has generously corrected this behavior and removed the automatic coercion of objects to array. With, DataWeave 2.0, a similar script will generate an error (in preview mode, as well as at runtime)
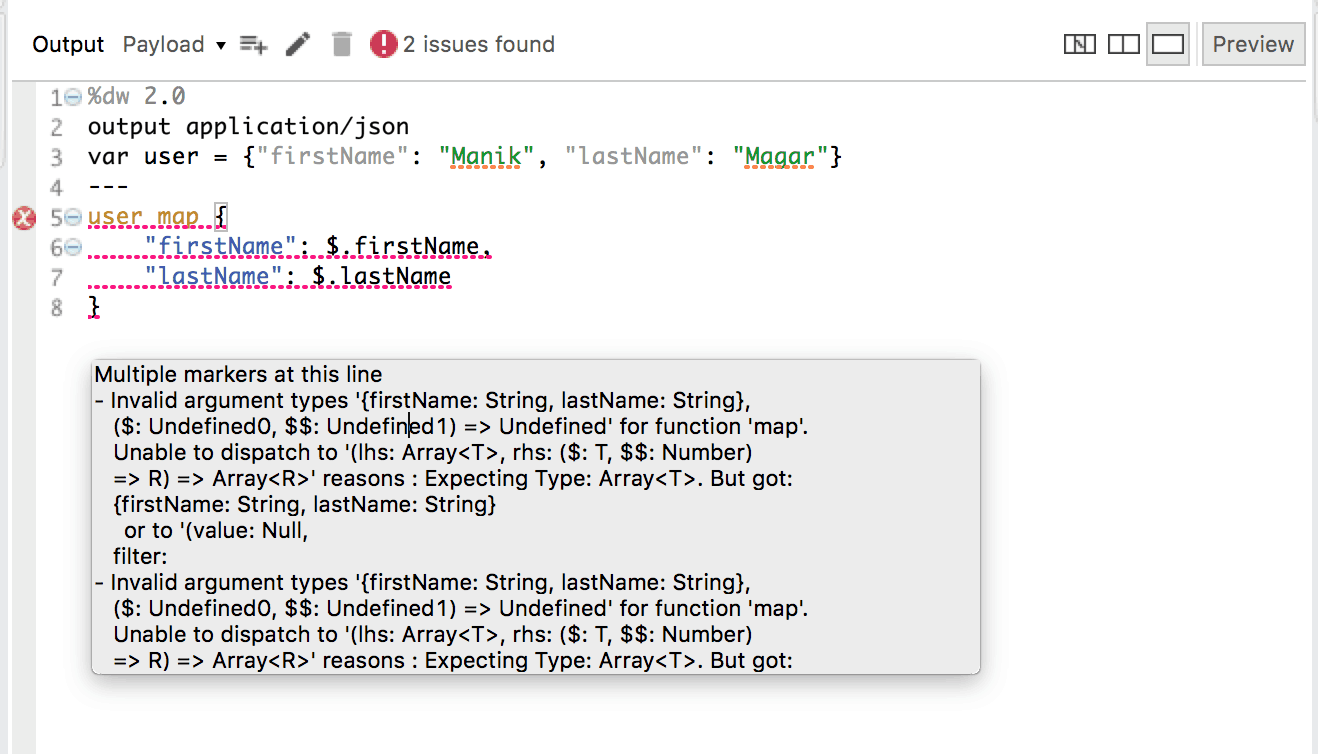
| Did you notice the error details shown in studio 7? They are so detailed and clear! Yet Another Useful Change! |
In my opinion, this change can definitely safeguard users from having unexpected output and data corruption in the downstream systems.
2.1.2 Overloaded Functions
In DataWeave 2.0, the functions filter and groupBy are overloaded to operate on objects. This could be useful to create sub-objects from a large object.
Consider an object {"firstName": "Manik", "lastName": "Magar", "Address Line1" : "Address line 1"}and we want to create another object with all the properties where value contains ‘Ma’.
With DataWeave 1.0, we will need to use mapObject and then map all key-value pairs conditionally. Something like the listing below:
%dw 1.0
%output application/json
%var user = {"firstName": "Manik", "lastName": "Magar", "Address Line1" : "Address line 1"}
---
name : user mapObject {
('$' : '
{
"name": {
"firstName": "Manik",
"lastName": "Magar"
}
}
In DataWeave 2.0, we can leverage the overloaded function of filter which allows us to operate on objects and achieve the same result but with shorter code.
%dw 2.0
output application/json
var user = {"firstName": "Manik", "lastName": "Magar", "Address Line1" : "Address line 1"}
---
name : user filter ($ contains "Ma")
Above one-line and simple code generates exact same output as in Listing:2.1.1.B. To understand the difference, if you write that filter function in DataWeave 1.0, the output will not be an object but an array of values satisfying the given condition.
{
"name": [
"Manik",
"Magar"
]
}
Similarly, groupByfunction has been overloaded to allow invoking three-argument lambda on object:
%dw 2.0
output application/json
var user = {"firstName": "Manik", "lastName": "Magar", "Address Line1" : "Address line 1"}
---
user groupBy ((value, key, index) -> if (key contains 'Name') "Names" else "Address")
|
Running this script against our user object, will partition (group) the object as below -
{
"other": {
"Address Line1": "Address line 1"
},
"Names": {
"firstName": "Manik",
"lastName": "Magar"
}
}
In DataWeave 1.0, the lambda signature is (value, index) so it is not possible to write a similar group by on an object. |
If you run groupBy on an object in DataWeave 1.0, it does not output keys which could be another problem.
%dw 1.0
%output application/json
%var user = {"firstName": "Manik", "lastName": "Magar", "Address Line1" : "Address line 1"}
---
user groupBy ((value, index) -> "Name" when (value contains 'Ma') otherwise "Address")
{
"Address": [
"Address line 1"
],
"Name": [
"Manik",
"Magar"
]
}
To achieve an output like Listing:2.1.1.F in DataWeave 1.0, we will need to take an approach similar to that shown in Listing:2.1.2.A.
2.1.3 Adding a Third Parameter
DataWeave 2.0 has added index as a 3rd parameter to mapObject, pluck, filter, and groupBy. Some of these functions also have index in DataWeave 1.0, but as a second parameter.
Consider the two code listings below:
%dw 1.0
%output application/json
%var user = {"firstName": "Manik", "lastName": "Magar", "addressLine1" : "Address line 1"}
%var userList = [{"firstName": "Manik", "lastName": "Magar", "addressLine1" : "Address line 1"},
{"firstName": "Om", "lastName": "Magar", "addressLine1" : "Address line 2"}
]
---
{
mapObject: user mapObject (value, key) -> {
'$key': value
},
pluck: user pluck (value, key) -> (key ++ '-' ++ value),
filter: user filter ((value, index) -> (index < 1)),
filter2: userList filter (value, index) -> (value.firstName contains 'Ma'),
groupBy1 : user groupBy ((value, index) -> (index < 1)),
groupBy2 : userList groupBy ((value, index) -> value.lastName)
}
%dw 2.0
output application/json
var user = {"firstName": "Manik", "lastName": "Magar", "addressLine1" : "Address line 1"}
var userList = [{"firstName": "Manik", "lastName": "Magar", "addressLine1" : "Address line 1"},
{"firstName": "Om", "lastName": "Magar", "addressLine1" : "Address line 2"}
]
---
{
mapObject: user mapObject (value, key, index) -> {
'$key-$index': value
},
pluck: user pluck (value, key, index) -> (key ++ '-' ++ index ++ '-' ++ value),
filter: user filter ((value, key, index) -> (index < 1)),
filter2: userList filter ((value, index) -> (index < 1)),
groupBy1 : user groupBy ((value, key, index) -> (index < 1)),
groupBy2 : userList groupBy ((value, index) -> value.lastName)
}
Listing 2.1.3 - A vs B
- The third parameter index has been added to mapObject function. This could be useful if you want to iterate on object properties based on property indices.
- There is an addition of a third index parameter to pluck, similar to mapObject.
- The filter function had index parameter in DataWeave 1.0 too, but when an object is passed to filter function, the index moves to the third place and a new second param key is introduced to the lambda. This is a great addition to operate over objects.
- There is NO change to filter lambda when input is a collection.
- Similar to filter on an object, groupBy for an object also gets key as new second param and index moved to third.
- There is NO change to gruopBy when input is a collection.
2.1.4 Allow NULL Input
Things happen, payloads becomes null sometime and when that happens, script starts failing. In DataWeave 1.0, functions will error out due to null input.
In DataWeave 2.0, map, mapObject and filter functions have been modified to accept NULL input and when that happens, they just return NULL.
Consider the DataWeave 1.0 and 2.0 scripts below:
{!{code class="hljs javascript"}!}czoxODU6XCIlZHcgMS4wJWR3IDEuMCUKb3V0cHV0IGFwcGxpY2F0aW9uL2pzb24KLS0tCnsgCiB1c2VyOiBudWxsIGZpbHRlciAoJC57WyYqJl19Zmlyc3ROYW1lID09IFwnTWFuaWtcJyksCiAKIHVzZXI6IG51bGwgbWFwT2JqZWN0IHsgCiAgIFwnJCRcJzogJCAKIH0sCiB1c2VycyA6IG57WyYqJl19dWxsIG1hcCB7IAogICAgICAgbmFtZTogJC5maXJzdE5hbWUgCn0KfVwiO3tbJiomXX0={!{/code}!}
All of the above mappings in DataWeave 1.0 will fail to compile due to NULL input.
%dw 2.0
output application/json
---
{
user: null filter ($.firstName == 'Manik'),
user: null mapObject {
'$': $
},
users : null map ((value, index) -> value.firstName)
}
All these mappings in DataWeave 2.0 will not fail but will generate the output below.
| Whether this is acceptable output or not, depends on your use case. You should consider the null input case and handle it appropriately. |
{!{code class="language-json hljs" data-lang="json"}!}czo0ODpcInsKIFwidXNlclwiOiBudWxsLAogXCJ1c2VyXCI6IG51bGwsCiBcInVzZXJzXCI6IG51bGwKfVwiO3tbJiomXX0={!{/code}!}
NULL for map is allowed when lambda is used and returns a single value that can be made null i.e. (T, Number) → Boolean format. For example, consider below mapping that tries to output a key-value pair, but will error out in DataWeave 2.0 too. |
users : null map ((value, index) -> (name: value.firstName))
And that summarizes DataWeave changes in headers and in the body (regarding iterative functions)! Check out my upcoming post, where I will further discuss DataWeave 2.0 body changes by focusing on operator changes as well as other differences.
This article first appeared on JavaStreets.
) when ($ contains 'Ma') }
In DataWeave 2.0, we can leverage the overloaded function of filter which allows us to operate on objects and achieve the same result but with shorter code.
Above one-line and simple code generates exact same output as in Listing:2.1.1.B. To understand the difference, if you write that filter function in DataWeave 1.0, the output will not be an object but an array of values satisfying the given condition.
Similarly, groupByfunction has been overloaded to allow invoking three-argument lambda on object:
|
Running this script against our user object, will partition (group) the object as below -
In DataWeave 1.0, the lambda signature is (value, index) so it is not possible to write a similar group by on an object. |
If you run groupBy on an object in DataWeave 1.0, it does not output keys which could be another problem.
To achieve an output like Listing:2.1.1.F in DataWeave 1.0, we will need to take an approach similar to that shown in Listing:2.1.2.A.
2.1.3 Adding a Third Parameter
DataWeave 2.0 has added index as a 3rd parameter to mapObject, pluck, filter, and groupBy. Some of these functions also have index in DataWeave 1.0, but as a second parameter.
Consider the two code listings below:
Listing 2.1.3 - A vs B
- The third parameter index has been added to mapObject function. This could be useful if you want to iterate on object properties based on property indices.
- There is an addition of a third index parameter to pluck, similar to mapObject.
- The filter function had index parameter in DataWeave 1.0 too, but when an object is passed to filter function, the index moves to the third place and a new second param key is introduced to the lambda. This is a great addition to operate over objects.
- There is NO change to filter lambda when input is a collection.
- Similar to filter on an object, groupBy for an object also gets key as new second param and index moved to third.
- There is NO change to gruopBy when input is a collection.
2.1.4 Allow NULL Input
Things happen, payloads becomes null sometime and when that happens, script starts failing. In DataWeave 1.0, functions will error out due to null input.
In DataWeave 2.0, map, mapObject and filter functions have been modified to accept NULL input and when that happens, they just return NULL.
Consider the DataWeave 1.0 and 2.0 scripts below:
All of the above mappings in DataWeave 1.0 will fail to compile due to NULL input.
All these mappings in DataWeave 2.0 will not fail but will generate the output below.
| Whether this is acceptable output or not, depends on your use case. You should consider the null input case and handle it appropriately. |
NULL for map is allowed when lambda is used and returns a single value that can be made null i.e. (T, Number) → Boolean format. For example, consider below mapping that tries to output a key-value pair, but will error out in DataWeave 2.0 too. |
And that summarizes DataWeave changes in headers and in the body (regarding iterative functions)! Check out my upcoming post, where I will further discuss DataWeave 2.0 body changes by focusing on operator changes as well as other differences.
This article first appeared on JavaStreets.



