
Load balancing across multiple server instances is one of the amazing techniques and ways for optimizing resource utilization, maximizing throughput, and reducing latency to ensure high availability of servers in an environment where some concurrent requests are in millions from users or clients and appear in a very fast and reliable manner.
A Load Balancer software, which allows users or clients to distribute heavy traffic to a single IP across many servers backend using a number of different protocols and different algorithms that help to share the heavy processing data load across many backend nodes, rather than a single server or node to take the entire data workload, and thus it increases the performance. As said earlier, it also ensure the availability of identical servers or nodes especially in a cluster environment such that If one of our server nodes fails or is down, the data traffic is automatically distributed to the next other nodes without any interruption of service without letting the client or user knowing about from which server/nodes the response is actually coming from!
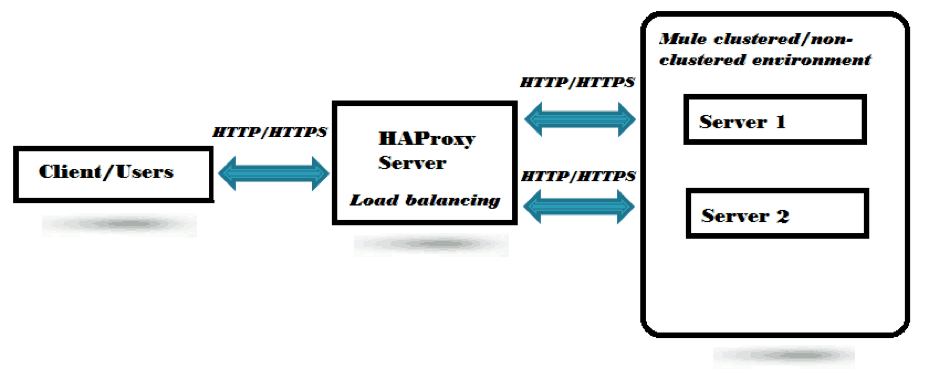
With Mule on-premises standalone servers which already supports clustering where workload are shared across multiple active-active nodes, however, requires a software load balancer for distributing the incoming HTTP request across its nodes which is exposing HTTP applications.
While I was searching for an open source, light weighted and easy to configure software-based load balancer for my Mule clustered and non-clustered environment, I was suggested by great David Dossot, former Mule Champion (also co-author of famous Mule in Action 2 book) to use HAProxy load balancer from his experience which indeed seems to be really amazing and perfectly fit with Mule environment without much effort in configuring.
In this blog we will be covering:-
- Load balancing between 2 different and independent on-premises Mule server instances located on 2 different operating system in a non-clustered environment.
- Load balancing between 2 different and independent on-premises Mule server instances located on 2 different operating system in a clustered environment.
Load balancing between Mule servers in a non-clustered environment:-
Let we have 2 different independent Mule instances located in 2 different location (one in Unix system another in Windows), and both are non-clustered. Let’s create 2 boxes applications that will be running on 2 different servers with HTTP endpoints.
Let’s first create the HTTP based application for the Mule server instance running on Unix system:-
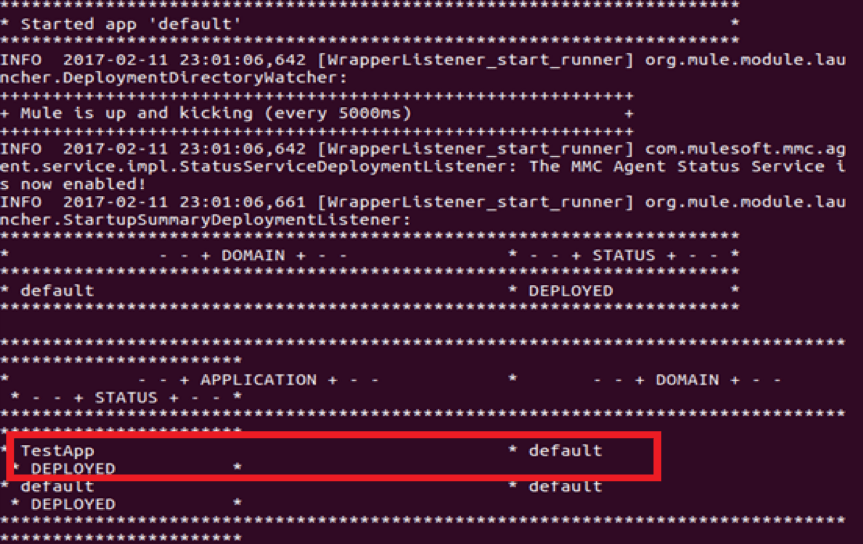
Now, let’s deploy the application in the Mule server manually under <MULE_HOME>/apps folder and we will see the application is deployed in Unix box:-
We will now modify a bit the same flow and will be deploying in the Windows system :-
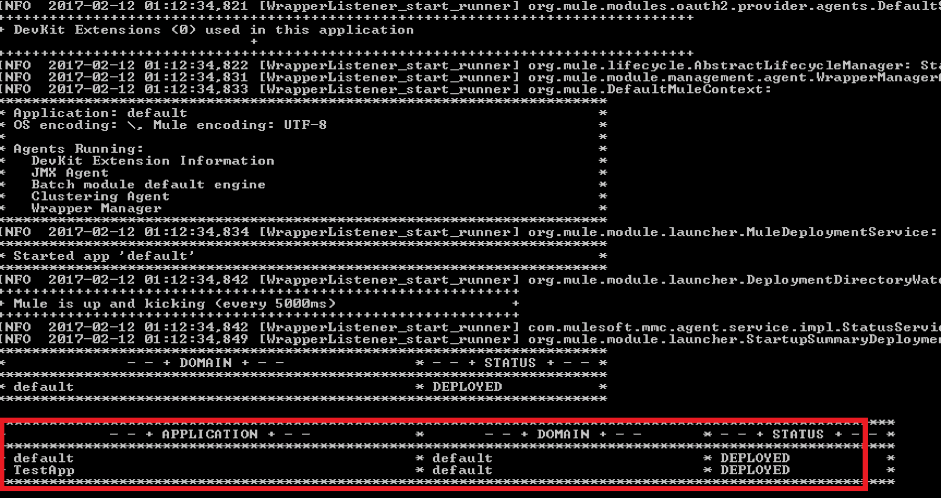
We will follow the same procedure to deploy the application in the Mule server manually under <MULE_HOME>/apps :
All set and all done! We will be testing both the application independently in the browser.
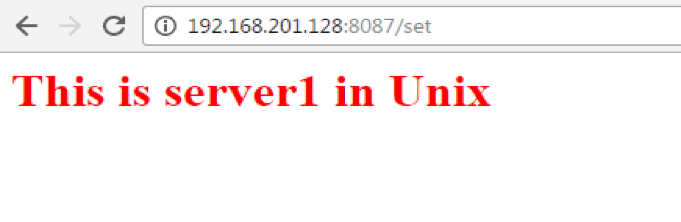
First, we will hit the URL:- http://192.168.201.128:8087/set of the application deployed in Unix system. Please note that the URL format will be HTTP://<ip address of the system>:8087/set, and here 192.168.201.128 is the IP address of my Unix system and here what we get:-
Similarly, we will hit the URL:- http://192.168.0.100:8087/set of the application deployed in Unix system. Again, here the URL format will be http://<ip address of the system>:8087/set and 192.168.0.100 are the IP address of my Windows system. We will get the following:-
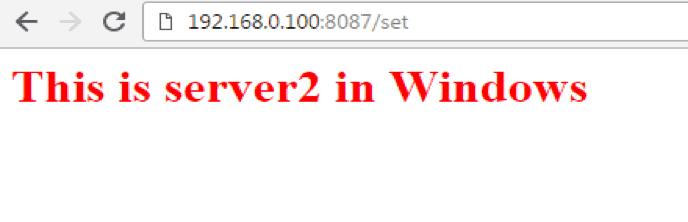
As we can see, both are independent servers running on 2 different boxes with the HTTP application deployed under then accepting HTTP request from client/users.
Configuring load balancing:-
As we had already discussed, we will be configuring a software based load balancing software to distribute the HTTP request between both these independent Mule servers, and for this, we will be using the HAProxy load balancer. We will be installing the HAProxy load balancer in our Unix system and will be configuring the configuration file located in the location /etc/proxy/haproxy.cfg.
A snippet of the haproxy.cfg file is as follows:-
If we see above part of the configuration, we will find that, we have configured the HAProxy load balancer to listen on the port 9001 from the users/clients:-
And configured both the backend Mule servers located in both the Unix and Windows boxes:-
Interestingly, we can also see that the algorithm configured here to distribute the request to the backend Mule servers is configured as Round Robin:-
Also, here we can see that we have configured HAProxy Stats on port 9002 to get information about data transfer, total connection, server state, etc. with an admin password:-
Once done with the configuration, we will restart the HAProxy server and hit the single HAProxy URL that will do the load balancing for us hitting and distributing the workload to the backend servers with the URL:- http://192.168.201.128:9001/set . Again not to forget here the URL format will be http://<ip address of the system>:9001/set and 192.168.201.128 are the IP address of my Unix system and it’s bind with 9001 port:-
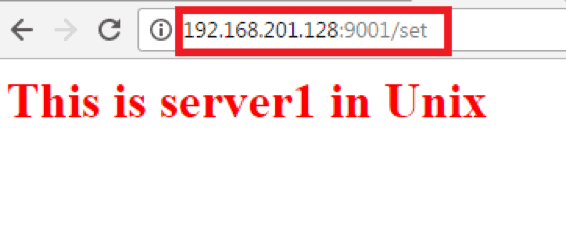
So, we can see it’s distributing the workload to the Mule server located in Unix box.
And now, if we hit the same URL again, we will see the workload is distributed to the next Mule server located in Windows box in a Round Robin fashion sharing equal workload:-

Wonderful, isn’t it?
We can configure more options with HAProxy load balancers like adding more different servers or maximum connection parameter, priority of some URLs, etc. and much more.
So, if we go the URL:- http://192.168.201.128:9002/haproxy?stats which we have configured as HAProxy Stats on port 9002:-
After entering the username & password, we can login into the statistic portal of HAProxy here we will get all the different information about the all the frontend and backend servers like Mule servers located in both the boxes:-
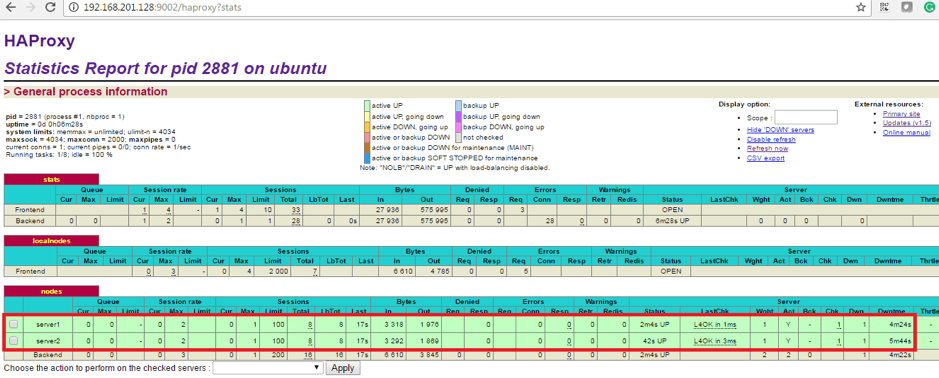
We can also enable/disable any backend servers dynamically from here. If a backend server node is down for some reason, the load will share by other backend server node and this statistic portal will immediately reflect the node that is down.
Load balancing between Mule servers in a clustered environment:-
We will now see how it behaves in a clustered environment. So, for doing this, we will configure and bring both the Mule server located on different boxes (Windows and Unix) under a cluster. We will configure the cluster using Mule mmc console for on-premises servers.
As we all know, how to configure Cluster with Mule MMC console, I am skipping those steps. If you still wondering where to find the steps, you can always refer here.
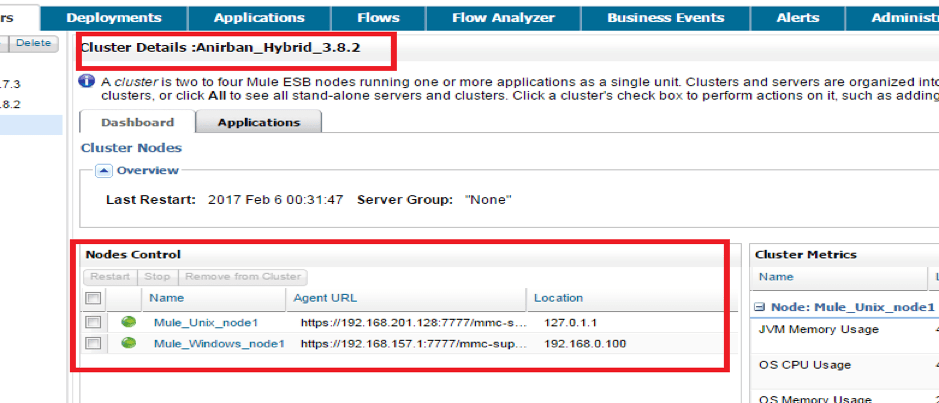
Now, we can see that we have created the cluster and brought both the Mule server under the cluster as below:-
We will be creating the following Mule flow and deploy the same application in both the server under the same cluster:-
We will be using Mule mmc console to deploy this application, so that the same application gets deployed in both the servers:
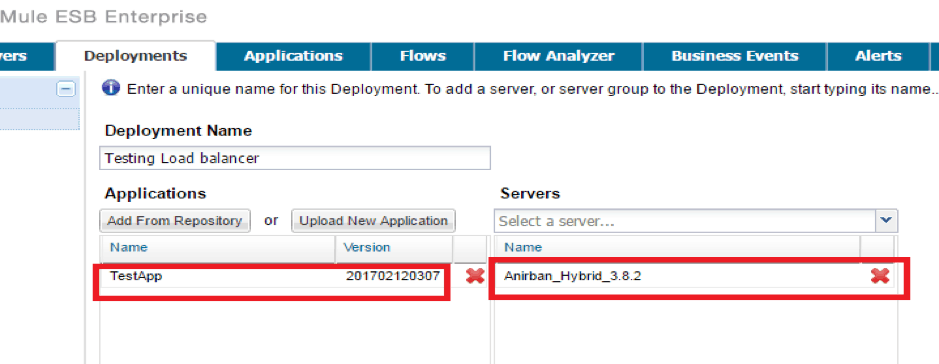
Once deployed, both the servers will have the same application running on it and we will get the same response whichever server we call.
Since we have already registered our servers with HAProxy configuration; we don’t need to do anything more here.
So, on calling the HAProxy URL:- http://192.168.201.128:9001/set, we will get the following in browsers:-
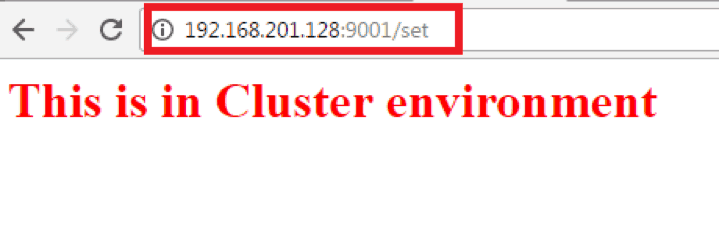
No matter how many times we call, we will get the same response.
The advantage of having a load balancer on on-premises cluster environment is the client or user will be unable to know from which server/nodes the response is actually coming from. Since, both the Mule servers have exactly the same HTTP application deployed in it, the client or user will get the same response every time they call. Even in the case if a backed nodes are failed or down, the load balancer will continue to distribute the workload to the other available live server without any interruption ensuring high availability of the server.
Hope you enjoyed the article; please put your feedback in the comment section below.



