
My first two posts in this Mule 4 blog series were on scaling your APIs and reactive programming in our newest version of Mule runtime engine. This blog dives into thread management and auto-tuning.
Mule 4 eradicates the need for manual thread pool configuration as this is done automatically by the Mule runtime.
Centralized thread pools
Thread pools are no longer configurable at the level of a Mule application. We now have three centralized pools:
- CPU_INTENSIVE
- CPU_LITE
- BLOCKING_IO
All three are managed by the Mule runtime and shared across all applications deployed to that runtime. A running Mule application will pull threads from each of those pools as events pass through its processors. The consequence of this is that a single flow may run in multiple threads. Mule 4 optimizes the execution of a flow to avoid unnecessary thread switches.
HTTP thread pools
The Mule 4 HTTP module uses Grizzly under the covers. Grizzly needs selector thread pools configured. Java NIO has the concept of selector threads. These check the state of NIO channels and create and dispatch events when they arrive. The HTTP Listener selectors poll for request events only. The HTTP Requester selectors poll for response events only.
There is a special thread pool for the HTTP Listener. This is configured at the Mule runtime level and shared by all applications deployed to that runtime. There is also a special thread pool for the HTTP Requester. This is dedicated to the application that uses an HTTP Requester. So 2 applications on the one runtime both using an HTTP Requester will have one selector pool each for that HTTP Requester. If they both use an HTTP Listener they will share the one pool for the HTTP Listener.
Thread pool responsibilities
The source of the flow and each event processor must execute in a thread that is taken from one of the three centralized thread pools (with the exception of the selector threads needed by HTTP Listener and Requester). The task accomplished by an event processor is either 100% nonblocking, partially blocking, or mostly blocking.

The CPU_LITE pool is for tasks that are 100% non-blocking and typically take less than 10ms to complete. The CPU_INTENSIVE pool is for tasks that typically take more than 10ms and are potentially blocking less than 20% of the clock time. The BLOCKING_IO pool is for tasks that are blocked most of the time.
Thread pool sizing
The minimum size of the three thread pools is determined when the Mule runtime starts up.
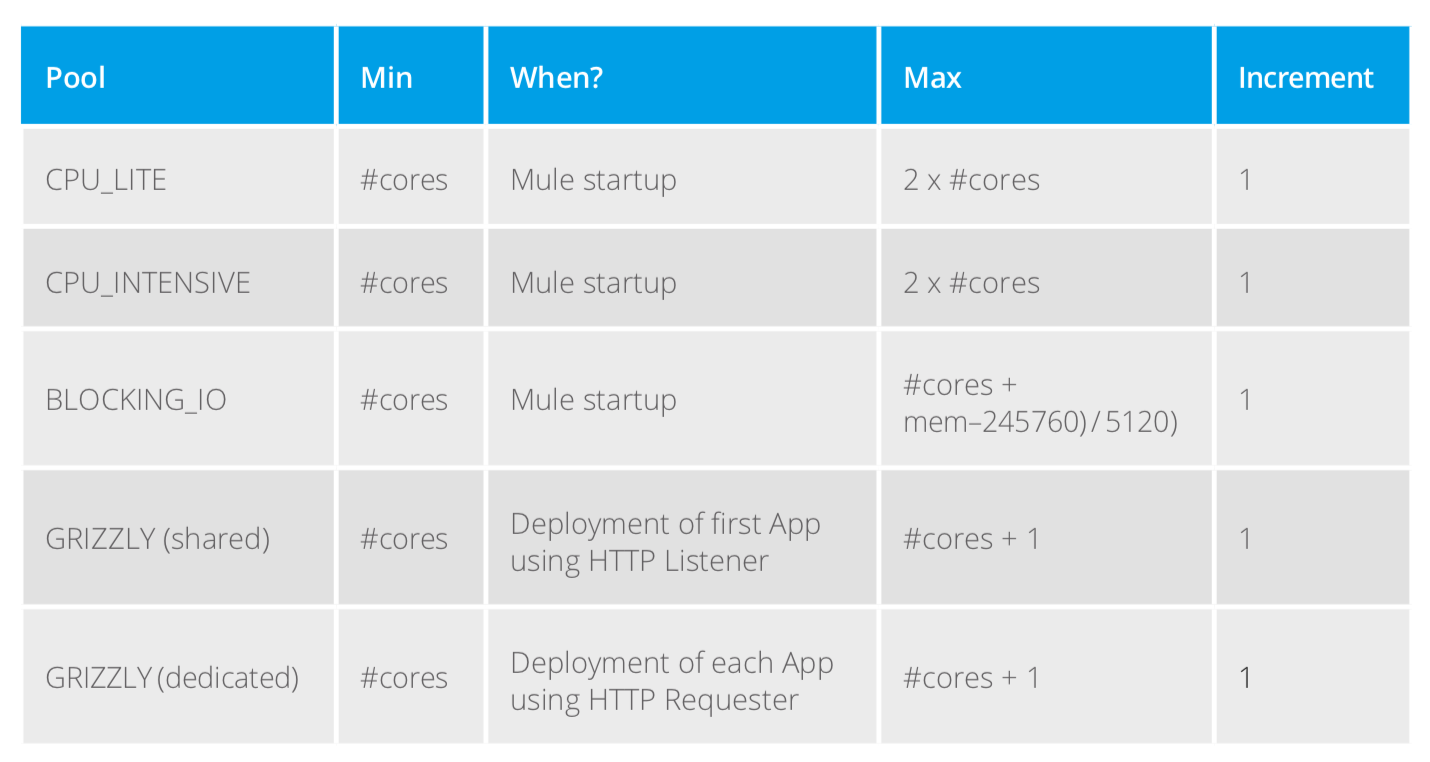
The minimum size of the shared Grizzly pool for the HTTP Listener is determined upon the deployment of the first app to the Mule runtime that uses an HTTP Listener. The size of the dedicated Grizzly for the HTTP Requester pool is determined upon deployment of each app that uses an HTTP Requester.
In all cases, the minimum number of threads equals the number of CPU cores available to the Mule runtime. Growth towards the maximum is realized in increments of one thread as needed.
The maximum size of the BLOCKING_IO thread pool is calculated based on the amount of usable memory made available to the Mule runtime. This is determined by a call the Mule runtime makes when it boots to Runtime.maxMemory().
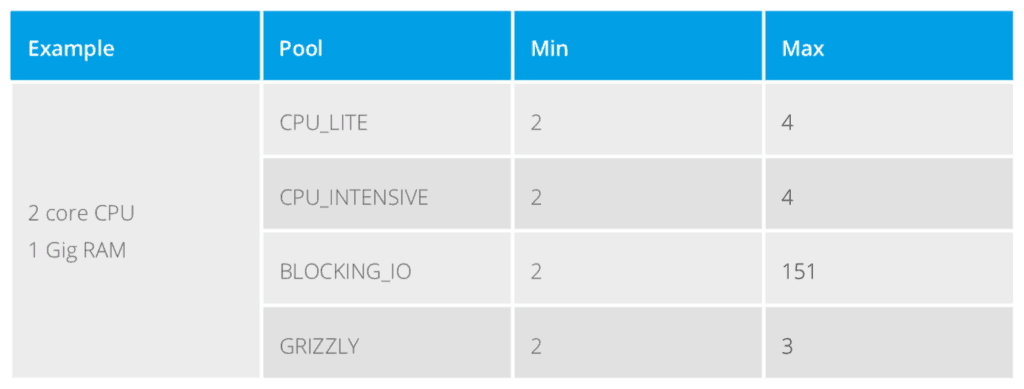
For a Mule runtime sitting on a 2 core / 1 Gig machine or container, the following table shows what the minimum and maximum values are for each thread pool.
Thread pool scheduler assignment criteria
In Java, the responsibility of managing thread pools falls on the Scheduler. It pulls threads from the pool and returns them and adds new threads to the pool. Each of the five pools we described above has its own Scheduler. When a Mule 4 app is deployed each of its event processors is assigned a Scheduler following the criteria outlined in the following table.

An important consideration is the handoff between each event processor. That is always executed on a CPU_LITE thread.
Over time our engineers will enhance modules to make their operations non-blocking.
Mule runtime example consumption of thread pools
The following diagrams show how threads are assigned in various types of Mule flow. Watch out for the red traffic light, which denotes a blocking operation (BLOCKING_IO). The amber traffic light denotes potential partial blocking (CPU_INTENSIVE). The space or handoff between each event processor is non-blocking and catered to by a CPU_LITE thread. Nevertheless, the optimization in the thread schedulers will avoid unnecessary thread switching so a thread from a given pool can continue to execute across processors as we shall see.
Typical thread switching scenario
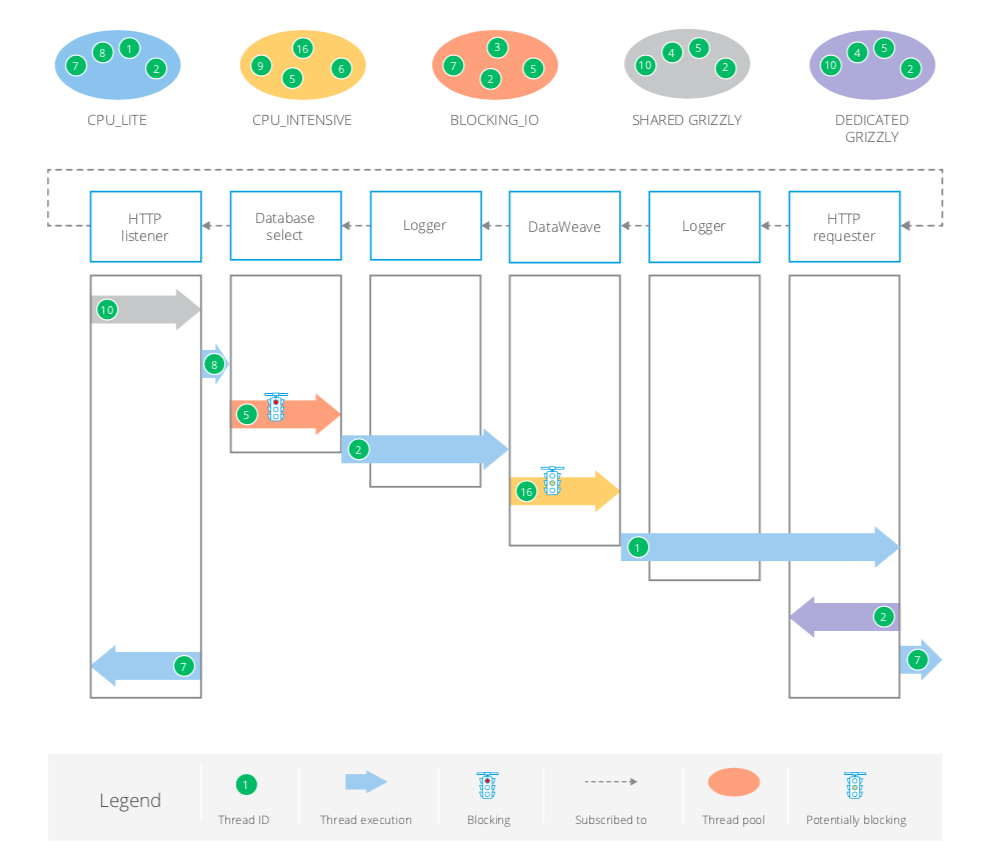
In this first scenario:
- SHARED_GRIZZLY Thread #10 receives the HTTP Listener request.
- CPU_LITE Thread #8 caters to the handoff between the HTTP Listener and the Database select operation.
- BLOCKING_IO Thread #5 must make the call to the database server and then wait for the result set to be sent back.
- A thread from CPU_LITE is needed for the Logger operation but Scheduler optimization allows for CPU_LITE Thread #2 to also be used for the handoff before and after it.
- CPU_INTENSIVE Thread #16 executes the DataWeave transformation. DataWeave always takes a thread from this pool regardless of whether blocking actually occurs.
- A similar optimization occurs on the second Logger and handoffs with CPU_LITE Thread #1 also making the outbound HTTP Requester call.
- DEDICATED GRIZZLY Thread #2 receives the HTTP Requester response.
- There is an optimization on the response after flow completion: CPU_LITE Thread #7 does the handoff back to the flow source (HTTP Listener) and also executes the response to the client.
Try scope with Transaction
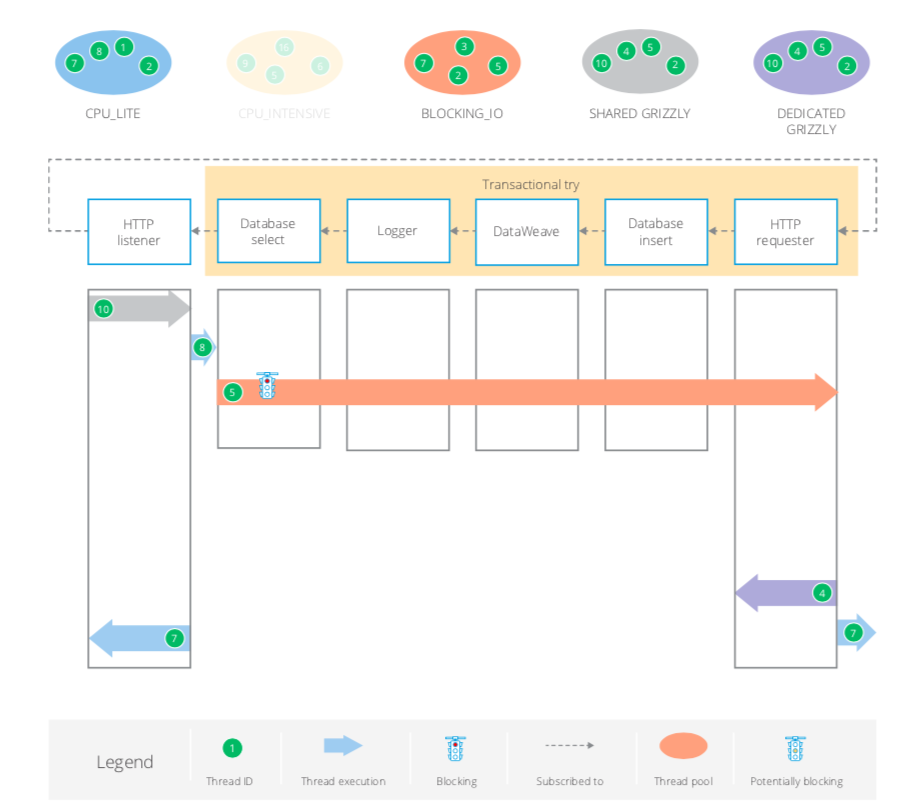
Here the Transactional Try scope mandates the use of a single thread. This will always be from the BLOCKING_IO pool regardless of what type of operations are contained within the scope.
JMS Transactional
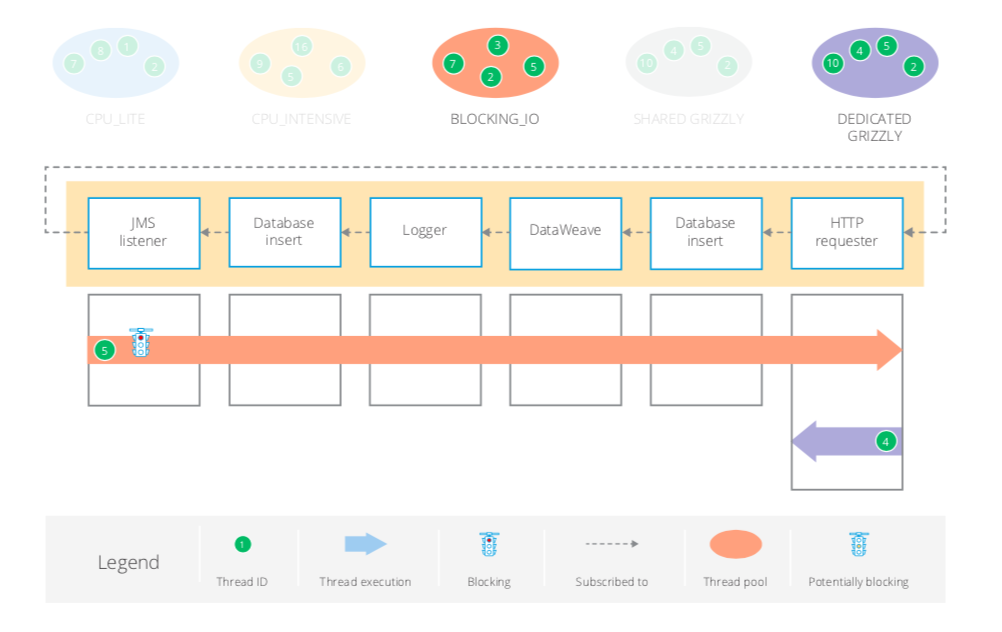
In this scenario the whole flow is transactional and requires a single thread from BLOCKING_IO up to the HTTP request.
JMS transactional with Async scope
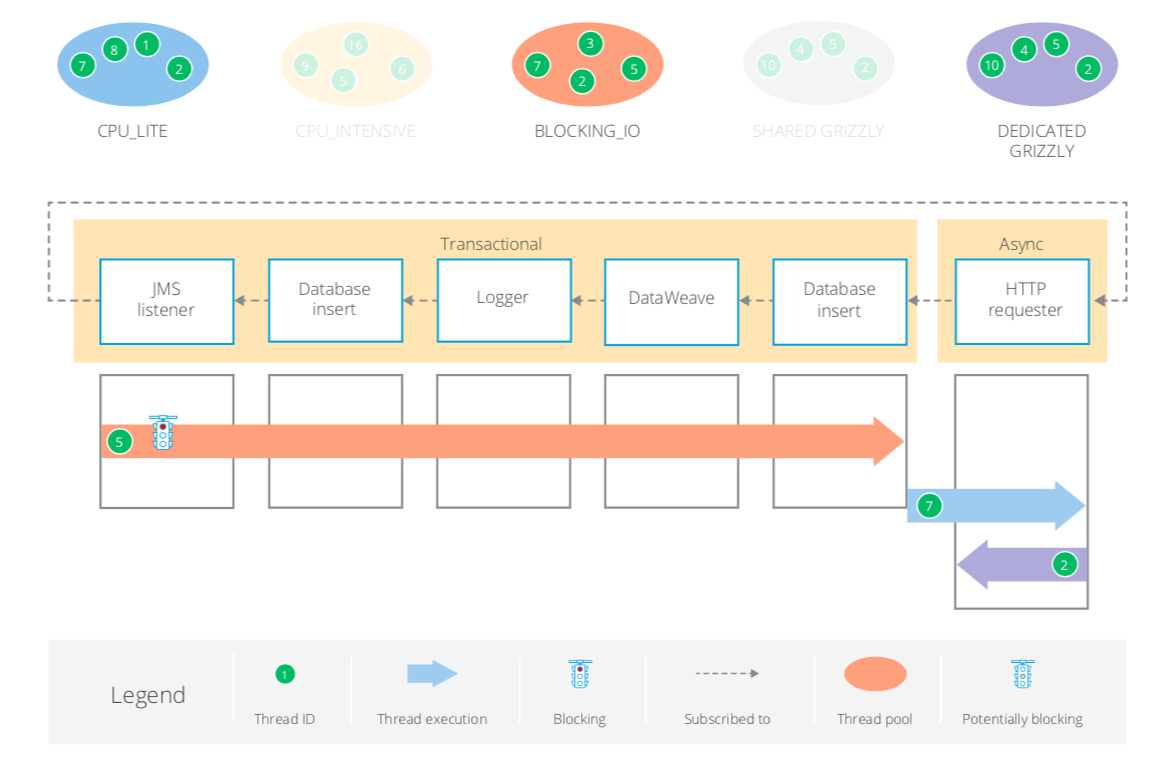
In this scenario, the Async scope ends the transaction and normal thread selection applies.
My next blog will dive into input streams in Mule 4. You can try Mule 4 today to see how you can address vertical scalability in an effective way or read our whitepaper, Reactive programming: New foundations for high scalability in Mule 4.



