
I have been asked so many times about DataWeave Performance during my time in the field. This is because developers try to find arguments to not use it when they realize that a new and proprietary programming language is introduced. Most of the time they have the same “natural response” of resolving the problem by going to the known and comfortable zone called “Java.”
This blog post will try to answer the performance question and give a set of basic and solid arguments to define the correct choice between DataWeave, Java custom code, and Mule Default Transformers to perform data transformations.
DataWeave performance versus Java custom code and MuleSoft’s Default Transformers
This benchmark is composed by 2-4-2-2-2, as in two files, four use cases, two different scenarios and environments, and DataWeave version 2. Read on if I’ve piqued your interest.
2 XML input files were used for this benchmark:
Products
A products XML representation, here is one node example:
1 Anypoint Security provides a layered approach to secure your application network. These layers work together to protect both the application network and the network’s individual nodes by controlling access to APIs, enforcing policies, and proxying all inbound or outbound traffic to mitigate external threats and attacks. Anypoint Security provides you with a dedicated endpoint to detect attacks and validate traffic without taxing your network implementations. 580 Anypoint Security 706
Bills
A bills XML representation, each bill contains a set of three products id referencing the products file, here is one node example:
1 204 314 584 67
4 Use Cases were performed:
UC1
Increase the product’s prices by 1% and return the updated products list using:
- DataWeave.
- XSLT Default Transformer.
- Custom Java Code Using DOM.
- Custom Java Code Using XPATH.
UC2
Upgrade the bill’s product information from products file, add listing_name and price using:
- DataWeave.
- XSLT Default Transformer.
- Custom Java Code Using XPATH.
UC3
Transform products to JSON, extract id, listing_name and price using:
- DataWeave.
- XSLT Default Transformer.
- Custom Java Code Using org.json.
UC4
Products descending order by price using:
- DataWeave.
- XSLT Default Transformer.
- Custom Java Code Using XPATH.
On 2 different Scenarios:
Small
100 Products and 50 Bills.
Medium
1000 Products and 500 Bills.
Using 2 Environments:
AWS Instance
Used to run JMeter tests and collect the results, the corresponding Availability Zone of this instance matches the CloudHub region of the deployed API.
Details:
AMI: Amazon Linux 2 AMI 2.0.20190115 x86_64 HVM gp2
Instance Type: t2.micro.
CloudHub
Used to run Small and Medium scenarios.
Details:
Runtime version: 4.1.5
Worker size: 1 vCores
Workers: 1
Region: US East (Ohio)
And the last 2 is because I used DataWeave version 2.
The collected results per scenario and use case are:
Note: only average values are considered for the comparison, min or max outliers are due to memory management and processing strategies of each method.
Small
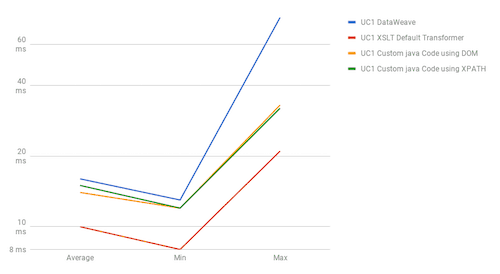
UC1

UC2

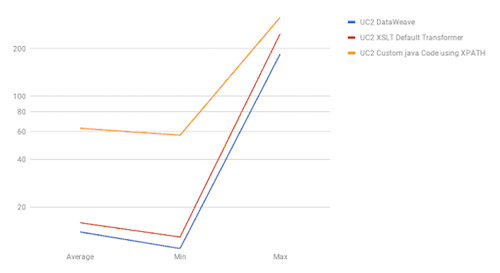
UC3

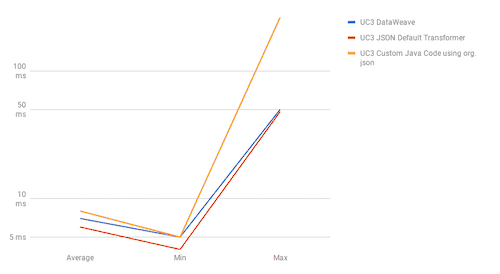
UC4

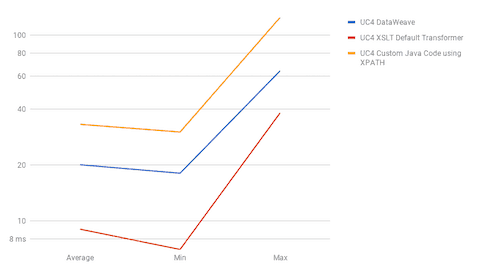
Medium
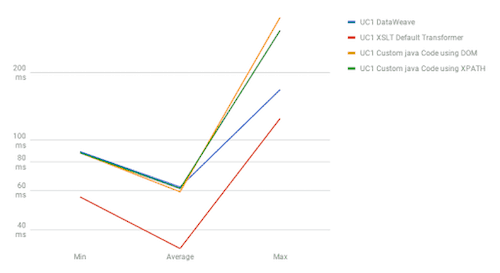
UC1

UC2


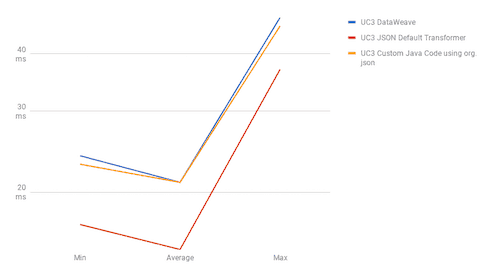
UC3

UC4

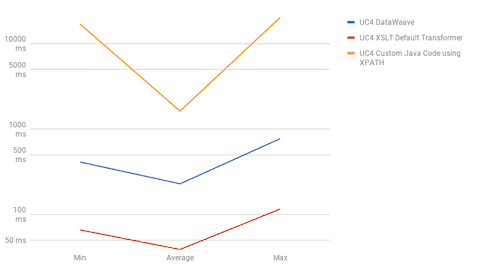
The results show DataWeave’s best performance is when we use it for joins, with UC2 results showing DataWeave as the fastest method in both scenarios. When we talk about sorting (UC4), DataWeave takes the second position between the most performant method, “Default Transformers,” and the worst performant, “Java Custom Code.” For use cases one and two, the fastest method is Default Transformers; DataWeave and Java Custom Code have barely the same performance in these use cases.
So far, we have talked about performance as a key differentiator or argument to select one method, but we need to consider more than the performance. Let’s talk about the total number of code lines written in this benchmark:
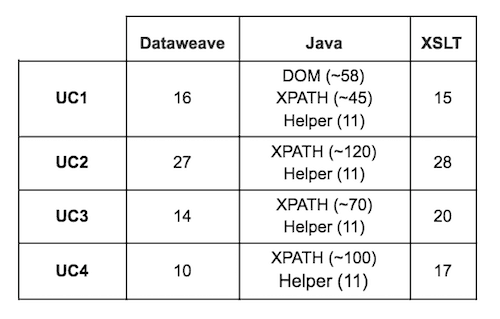
The numbers show higher amounts using Java code; XSLT and DataWeave are barely the same, but DataWeave has fewer lines of code written on every UC.
So at this point, we have:
- Same or better performance than Java Custom Code.
- Less amount of lines of code.
Seems like a good amount of arguments to start using DataWeave instead Java Custom Code. But in case you may need more, consider that, like other languages, DataWeave is hard in the beginning, but when you see how easy it is to deal with big transformations, you will love it. Also, the use of custom Java code is not a best practice as it may introduce future migration problems.
DataWeave is an amazing language. Give it a try and a chance, and if you have doubts, you can ask the community. Additionally, if you want to expand your knowledge, check out our DataWeave courses.



