Sometimes (more often than we think), less concurrency is actually more. Not too long ago, I found myself in a conversation in which we were discussing non-blocking architectures, tuning, and performance. We were discussing that tuning for those models often starts with “2 threads per core” (2TPC). The discussion made me curious about how Mule’s batch module would perform if tested by 2TPC. I knew beforehand that 2TPC wouldn’t be so impressive on batch, mainly because it doesn’t use a non-blocking threading model. However, I found myself thinking that the 16 thread default threading profile might be a little excessive (again, because sometimes less is more) and wanted to see what would happen if we tried it. You know, just out of curiosity.
Designing the Test
I explained my hypothesis to the mighty Luciano Gandini from our performance team. He pointed out that there were two different cases that needed to be tested:
- Jobs that are mainly IO bound, which spend most of their execution time performing IO operations (to disk, Databases, external APIs, etc)
- Jobs that are mainly CPU bound. They might as well do a fair amount of IO, but most of the processing time is spent on CPU operations (transformations, validations, etc).
GOTCHA: Because batch relies on persistent queues to support large datasets while guaranteeing reliability and resilience, no batch job is truly light on IO. However, because the impact of that fact is similar no matter how many threads you use, for the purpose of this test (and for that purpose only) we can pretend that factor doesn’t exist.
Luciano then designed two batch jobs, one IO intensive and one CPU intensive one. Each job was executed several times with a 1 million records dataset. The tests were executed in a 24-core computer (the performance guys have pretty amazing toys!) and a different threading profile was used on each run. These were the results:
IO bound Jobs
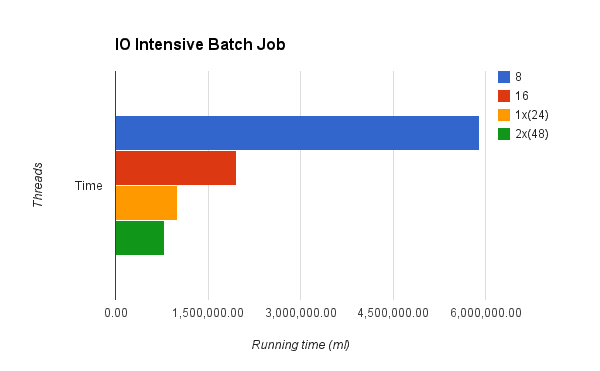
The two first runs used 8 and 16 threads, the later being much faster. That’s easy to explain – since the job is hard on IO, many threads will find themselves locked and waiting for the IO operation to finish. By adding more threads, you can have more work going on. Then, there was a third run which used 24 threads (1 per core). Again, this was faster but not by much. And again, this didn’t come as a surprise. Although there’s more work being done, the new threads also block on IO operations at basically the same time and by the same time, while adding an increasing penalty on context switch and thread administration penalty. The last run used 48 threads (true 2TPC) and while still faster, the improvement gained was not significant compared to the extra CPU and memory cost.
Conclusion: More threads do increase performance, but only to a certain extent, which you’ll find pretty fast. The 16 threads default was validated.
GOTCHA: If your job’s IO includes consuming an external API, adding more threads might turn out to be way more harmful than shown here. That’s because some APIs have limits in terms of how many calls can you perform a day or even how many you can perform concurrently. Exceeding those thresholds might result in your requests being rejected or throttled.
CPU bound jobs
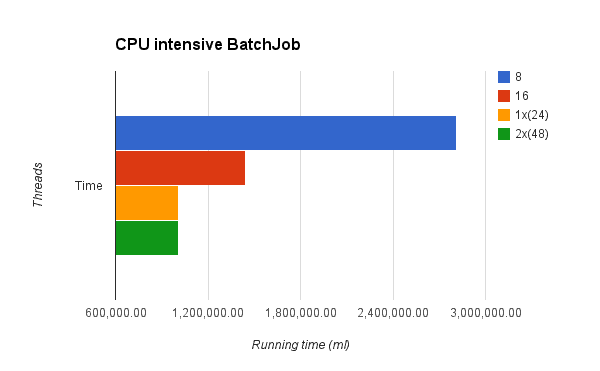
These results did come as a surprise. First of all, because the behavior was really similar for that of IO bound jobs, so the first hypothesis of the two cases being different was the first thing to be disproved by the test.
For the first two runs with 8 and 16 threads, the results were similar. 16 threads did the job in less than half the time. The big difference, however, was that the 24 and 48 runs gave almost the same running time. This is because the threads on this job didn’t spend any time at all being blocked by IO operations, so the overhead of the added threads pretty much consumed all the gained processing power. Gotta admit, I didn’t see that one coming.
Conclusion: The behavior is pretty similar no matter the nature of the job. Although for CPU intensive ones, the decay is more noticeable once the 16 threads barrier is surpassed. The 16 threads default was validated again.
Final thoughts
The good news is that it looks like we don’t need to change any defaults in batch. But most importantly, the results provided some lessons on tuning and performance which we weren’t expecting. Keep in mind however that no two jobs are born alike. You might as well have cases which don’t follow these trends. The purpose of this post is not to tell you what to do, but to give you ideas on how to test what you’re doing. Hope it helps on that regard.
We’d really like for you to share what kind of batch jobs you have and how they react to variations in the threading profile. Looking forward to validating these trends or getting more surprises!
Cheers.