
John Moses, Sr. Manager, and his daughter Monica Racha, Consultant, both at Capgemini, share how to integrate Snowflake and Kafka using MuleSoft. Both John and Monica are MuleSoft Certified developers and they presented this topic together during a Sydney MuleSoft Meetup. You can find a recorded version below.
This blog will cover a variety of topics including an overview of event-driven architecture, the MuleSoft Kafka Connector, the Snowflake Sink Connector, and how MuleSoft ties them all together. It is important to have a basic understanding of event-driven architectures, Kafka, and Snowflake to properly combine these systems using MuleSoft.
Event-driven architecture overview
An event-driven architecture is a two-way sync (request and reply) between databases and systems. We use it to chunk big sets of data into smaller chunks which are then streamed at continuous intervals so that we can handle huge amounts of data faster and with ease. However, this can be problematic because instead of having one set of integrated data, we will have multiple data channels.
How is all of this data going to be processed? This creates complex event processing. It’s when traditional integration methods, like TIBCO or Web Methods, are not current enough to adapt to the cloud-based complex event processing engine. What is needed is a powerful integration platform to seamlessly connect across multiple applications and support complex event processing.
Now that we have a basic understanding, let’s look at the scenario we’ll be referring to throughout the blog.
From an on-prem ESB to a cloud-based solution
This is a typical scenario happening around the world, specifically in the energy and utility sector. Data needs to be shared between retailers, distributors, generators, and the market hub to provide accurate billing data, spot pricing data, discounts, etc.
Problems with this solution include:
- All parties are running their B2B and B2M integration solutions on-Prem and at capacity with traditional ESB solutions.
- Sharing data between countries is more frequently requested and this traditional solution is not able to keep up with the demands.
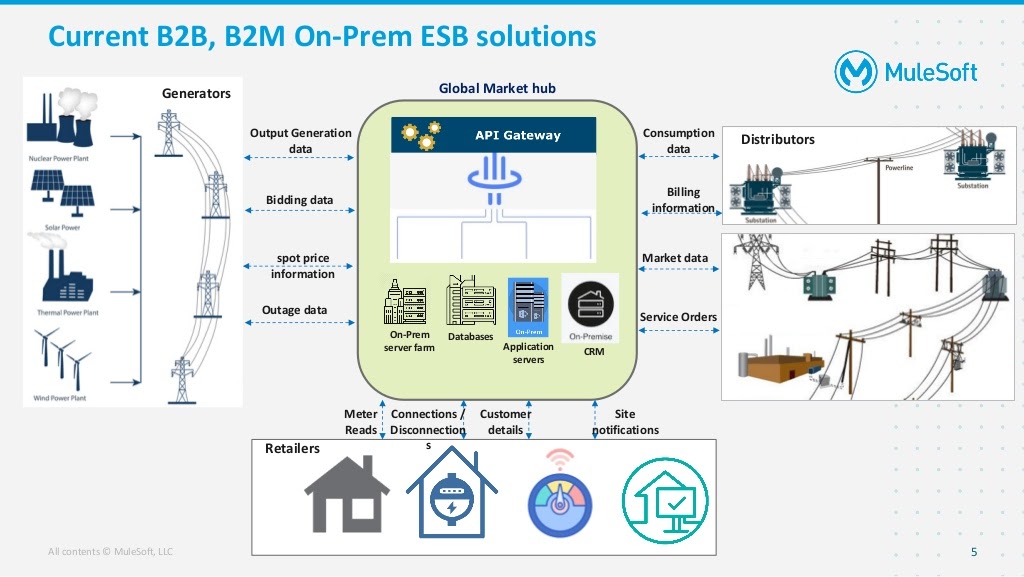
In the original on-prem solution above, the distributors are sharing the consumption data, billing, market data, and service orders for every action with the market hub. On the other end, we have generators who share generation, bidding, spot price, and outage data with the market hub. Lastly, we have the retailers sharing meter reads, connections/disconnections, customer details, and other personal data with the market hub. All of the data needs to be shared via on-prem causing the underlying systems to have long turn-around times affecting all of the various parties relying on the shared data.
Proposed solution using MuleSoft
We propose using MuleSoft to create a cloud-based API solution with an event-driven architecture. This includes connecting Snowflake and Kafka to build a B2B ecosystem to handle this problem and many more.
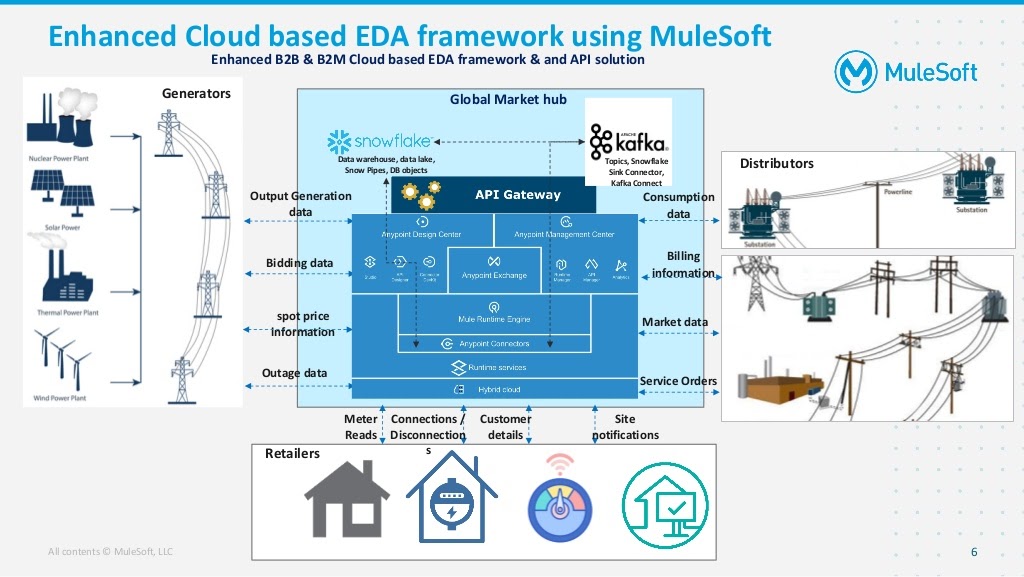
Here we have built a cloud-based solution rather than having it on-prem which can handle all of the same data, while being seamlessly integrated. The data now flows through Anypoint Platform.
Using Snowflake, Kafka, and Anypoint Platform to build a solution
We created a few different Mule flows to replicate some of the main components that can be seen in our diagram above. We have a market message processor that receives various market messages from all of the participants (distributors, generators, retailers) in API Manager. It processes the messages, gathers the underlying information, transforms it, and publishes it into a Kafka topic. Next, we have the MuleSoft Apache Kafka Connector and the Confluent Snowflake Connector. We configure MuleSoft’s Apache Kafka Connector to connect to a local instance of Kafka to publish the messages to the topic.
Additionally, the Confluent Snowflake Sink Connector listens to particular topics and streams the messages to a Snowflake staging table as soon as the messages from the participants arrive in their designated topics. Thus, all of the market messages will land in the Snowflake staging table. In an ideal scenario, we would have multiple topics for each retailer, distributor, and generator to drill down to have each topic for a particular business data domain such as for billing information. This helps the respective data flow solely through the designated pipeline without having to interact with or disturb any other business data. The Snowflake Sink Connector provides this connectivity mechanism out of the box.
Next, we built Snowflake Streams which are highly effective and make Snowflake one of the leading cloud-based data warehouses to build data lakes. Adding to this, we built a Snowflake outbound data processor to showcase the outbound connectivity from Snowflake. We utilized the Mule Generic JDBC Connector to connect to the Snowflake table to pull new record entries into the table.
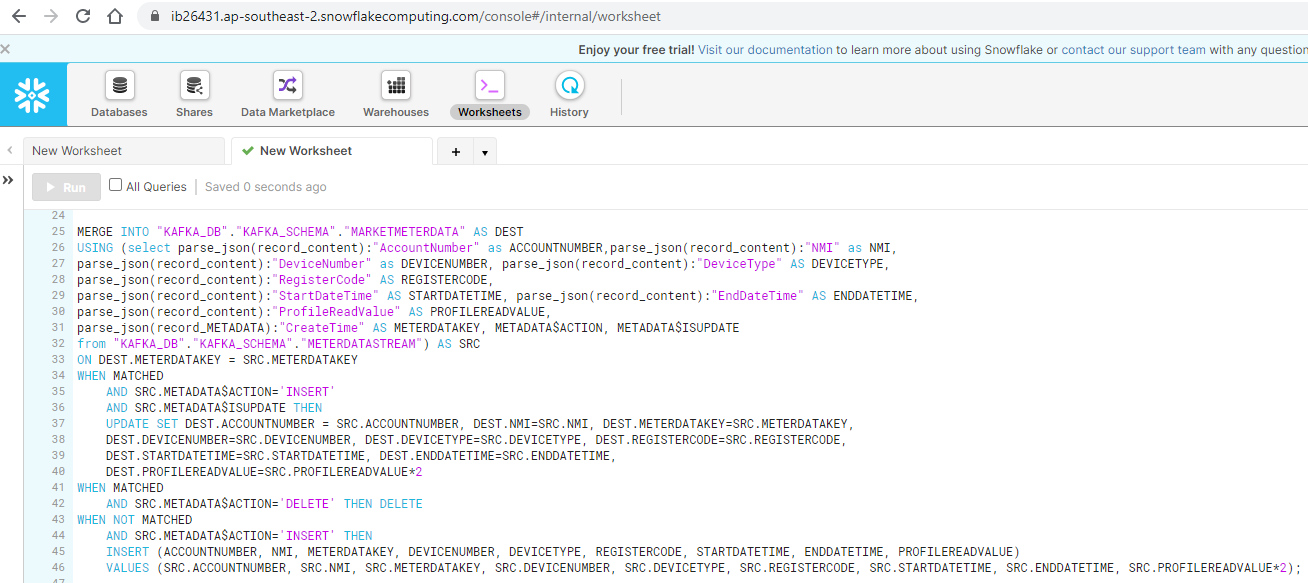
Now let’s see how we built our solution in a step-by-step tutorial by Monica.
Benefits of MuleSoft Cloud EDA+ API solution
One of the benefits of a MuleSoft Cloud EDA and API solution is that you can have a sustainable, reliable, and distributed streaming solution that runs on Anypoint Platform. It’s perfect for any global hubs that want to seamlessly design a solution and run it purely on Cloud. Having the likes of Kafka, Snowflake, and API-led architecture with MuleSoft, the solution becomes 100% scalable both vertically and horizontally. It also creates 4X faster Through-Puts (TPS) handling by MuleSoft Kafka connectors when compared to other messaging platforms. Lasly, using SnowPipes REST APIs allows millions of records from AWS S3 buckets to load in Snowflake in just a few seconds.
You can find the entire presentation here. If you have a technical topic you would like to present a MuleSoft Meetup, apply here!



