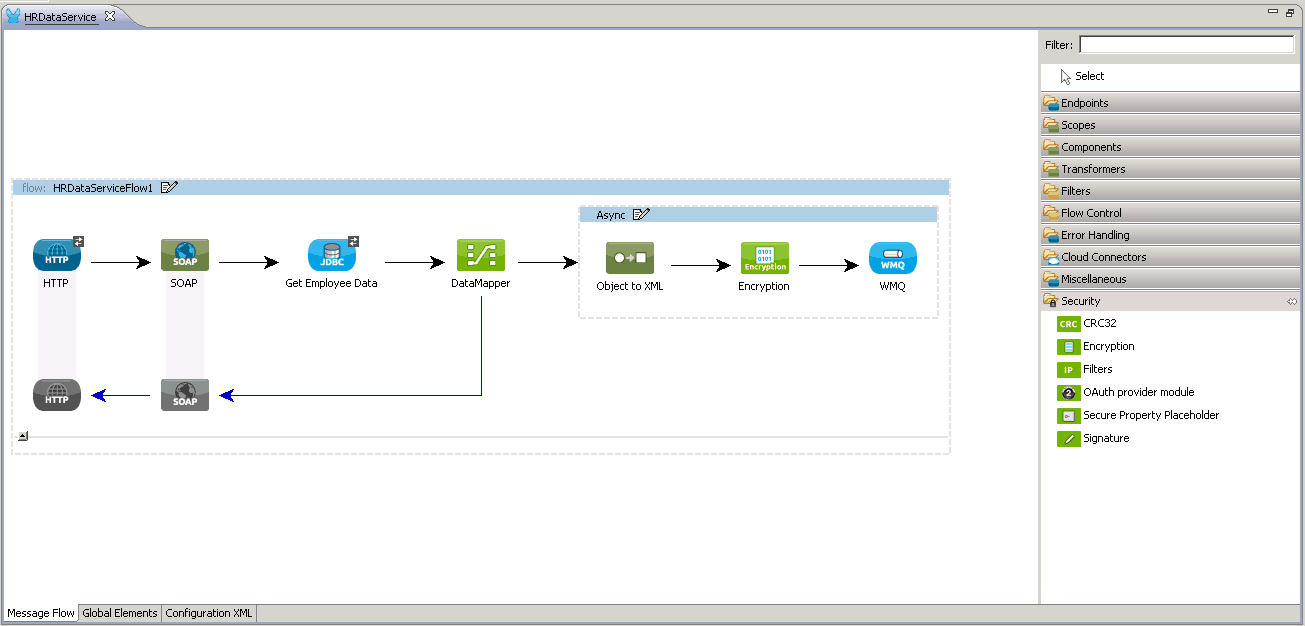
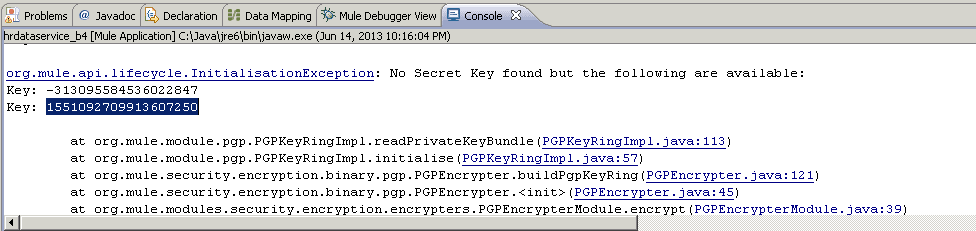
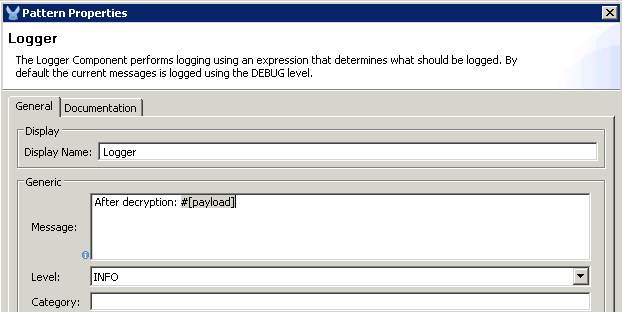
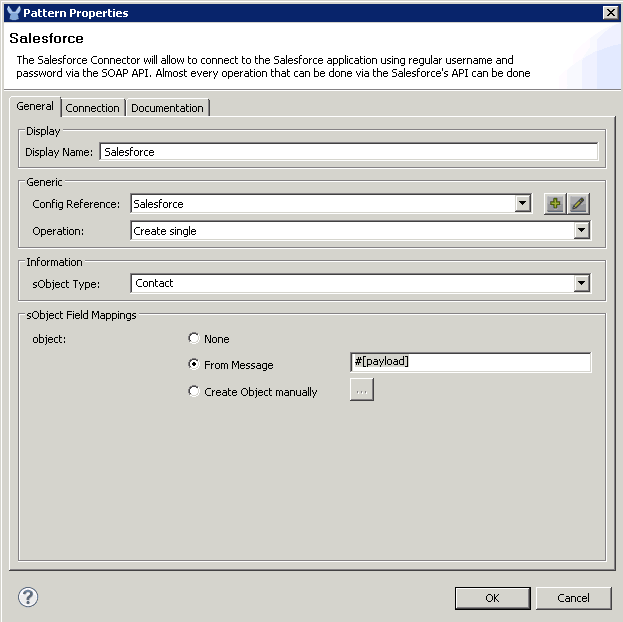
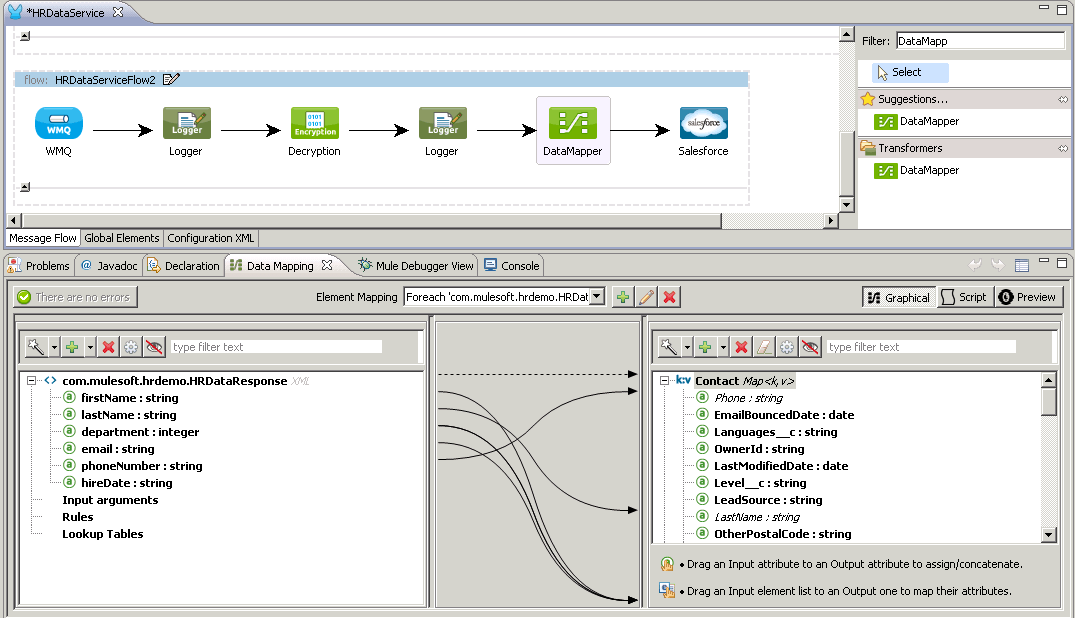
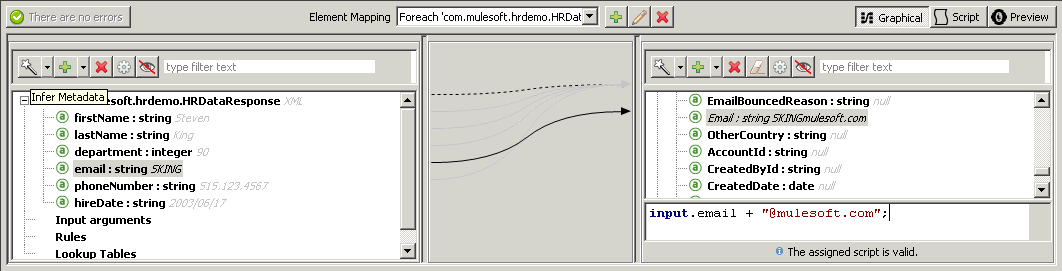
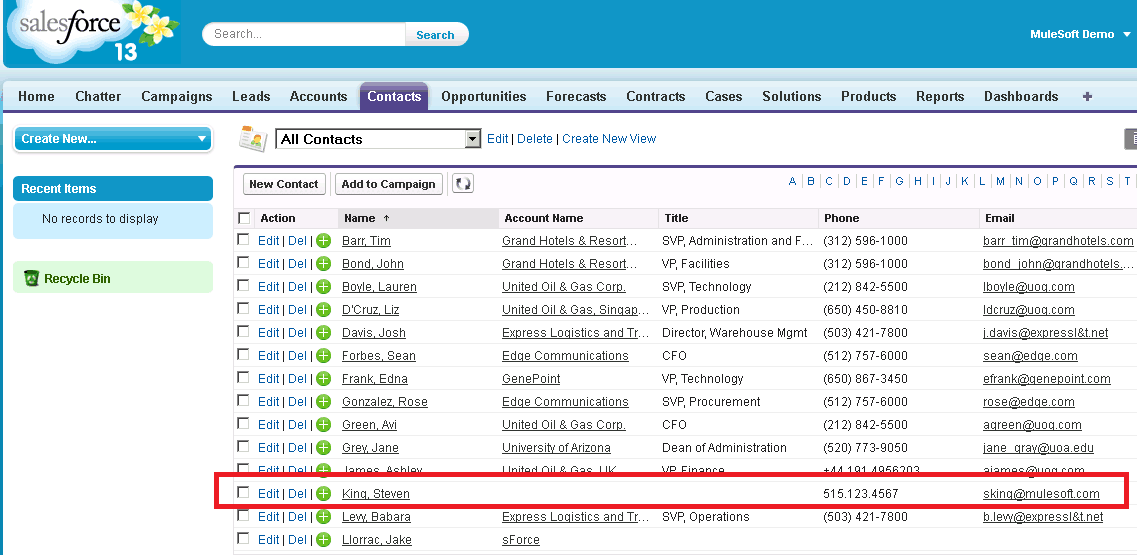
When you come from a class based programming language, doing objects in JavaScript feels weird: Where is the class keyword? How can I do inheritance?
As we are going to see, JavaScript is actually pretty simple. It supports class like definition of objects and single-inheritance out of the box.
But first, a small tip to change your reading experience. By using your browser JavaScript console, you can play with the examples without leaving this page:
- Chrome: MacOSX Cmd-Alt-J / Windows Ctrl-Shift-J
- Firefox: MacOSX Cmd-Alt-K / Windows Ctrl-Alt-K
- Safari: Cmd-Alt-C (only if you enable the Develop menu on Advanced Settings)
- IE8+: Press F12 and go to the console
The basics
Ok, all set. Now the first step, define an object:
var point = {x: 1, y: 2};
As you can see the syntax is pretty straight forward, and object members are accessed by the usual means:
point.x // gives 1
Also we can add properties at any time:
var point = {};
point.x = 1;
point.y = 2;
The elusive this keyword
Now lets move on to more interesting things. We have a function that calculates the distance of a point to the origin (0,0):
function distanceFromOrigin(x, y) {
return Math.sqrt(Math.pow(x, 2) + Math.pow(y, 2));
}
The same function written as a method of point looks like this:
var point = {
x:1, y:2,
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
If we evaluate: point.distanceFromOrigin(), the this keyword becomes point.
When you come from Java it may sound obvious, but as we go deep into the details of JavaScript, is not.
Functions in JavaScript are treated like any other value, it means that distanceFromOrigin doesn’t have anything special compared to the x and y fields. For example we can re-write the code like this:
var fn = function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
};
var point = {x:1, y:2, distanceFromOrigin: fn };
How this is determined?
JavaScript knows how to assign this, because of how distanceFromOrigin is evaluated:
point.distanceFromOrigin();
But doing just fn() will not work as expected: it will return NaN, cause this.x and this.y are undefined.
Confused? Lets go back to our initial point definition:
var point = {
x:1, y:2,
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
Since distanceFromOrigin is like any other value, we can get it and assign it to a variable:
var fn = point.distanceFromOrigin;
Again fn() returns NaN. As you can see from the two previous examples, when a function is defined there is no special binding with the object. The binding is done when the function is called: if the obj.method() syntax is used this is automatically set to the receiver.
It’s possible to explicitly set this?
JavaScript functions are objects, and like any object they have methods.
In particular a function has two methods apply and call, that executes the function but allows you to set the value for this:
point.distanceFromOrigin() // is equivalent to… point.distanceFromOrigin.call(point);
For example:
function twoTimes() {
return this * 2;
}
twoTimes.call(2); // returns 4
Defining common behavior
Now suppose that we have more points:
var point1 = {
x:1, y:2,
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
var point2 = {
x:3, y:4,
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
It makes no sense to copy & paste this snippet each time that you want to have a point, so a small refactoring helps:
function createPoint(x, y) {
var fn = function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
return {x: x, y:y, distanceFromOrigin:fn};
}
var point1 = createPoint(1, 2);
var point2 = createPoint(3, 4);
We can create lots of points in this way, but:
- It makes an inefficient use of memory:
fnis created for each point. - Since there is no relationship between each point object, the VM cannot make any dynamic optimization. (ok this is not obvious and depends on the VM, but it can impact on execution speed)
To fix these problems JavaScript has the ability to do a smart copy of an existing object:
var point1 = {
x:1, y:2,
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
var point2 = Object.create(point1);
point2.x = 2;
point2.y = 3;
Object.create(point1) uses point1 as a prototype to create a new object. If you inspect point2 it will look like this:
x: 2
y: 3
__proto__
distanceFromOrigin: function () { /* … */ }
x: 1
y: 2
NOTE:
__proto__is a non-standard internal field, displayed by the debugger. The correct way to get the object prototype is withObject.getPrototypeOf, for example:Object.getPrototypeOf(point2) === point1
This way of handling objects as copies of other objects is called prototype-based programming, and conceptually is simpler than class based programming.
The ugly syntax part
So far I told you the nice part of the history.
Object.create was added in JavaScript 1.8.5 (aka ECMAScript 5th Edition or just ES5). So, how objects were cloned in previous versions of the language?
Here comes the ugly syntax part. Every function is an object, so we can add properties to functions dynamically:
fn.somevalue = 'hello';
Suppose for a minute that we have Object.create. So we can use function objects and Object.create to get all the information required to copy and initialize objects in a single step:
// we store the "prototype" in fn.prototype
function newObject(fn, args) {
var obj = Object.create(fn.prototype);
obj.constructor = fn; // we keep this reference... just because we can ;-)
fn.apply(obj, args); // remember this will evaluate fn with obj as "this"
return obj;
}
Ok, but I told you that we don’t have Object.create yet, what we do?
JavaScript has a keyword that does the same as the newObject function:
newObject(fn); // is equivalent to.. new fn()
NOTE: For explanation purposes I’ve shown how to implement
newusingObject.create. Take account thatnewis a language keyword, and even when it’s semantically equivalent tonewObject, the implementation is different. In fact for some JavaScript engines creating objects withnewis slightly faster thanObject.create.
AlsoObject.createis a relative recent addition, in old engines like IE8, the usual trick is to implement it usingnew. I showedObject.createfirst because it makes things easy to understand.
Why JavaScript has this strange use of functions? I don’t know. My guess is that probably the language designers wanted to resemble Java in some way, so they added a new keyword to simulate classes and constructors.
By using new you can write the previous point example like this:
// the point constructor
function Point(x, y) {
// "this" will be a copy of Point.prototype
this.x = x;
this.y = y;
}
// the prototype instance to copy
Point.prototype = {
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
Now each time that we do new Point(x, y) we get a new point:
var point1 = new Point(1, 2); var point2 = new Point(2, 3);
Things to know about prototype and constructor
When you evaluate obj.x, the engine follows this logic:
- Does obj defines x? If the answer is yes, then x from obj is used.
- Otherwise search for x in the prototype.
- If not found yet, continue with the prototype of the prototype.
As you can see this is similar to the method lookup used in class based programming languages, just replace prototype with super class.
But since the prototype field is almost like any other field, we can do cool dynamic stuff like adding new methods to existing instances:
var hello = "Hello";
String.prototype.display = function () { console.log(this.toString()); }
hello.display()
And what about constructor?
Every object in JavaScript has a constructor property, even if you don’t define it. When the object created using new the constructor property points to the function used to create the object.
Single inheritance
We can apply what we learned to do single-inheritance:
// the "super class"
function Point(x, y) { this.x = x; this.y = y; }
Point.prototype = {
distanceFromOrigin: function () {
return Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2));
}
};
// the "sub class": ColoredPoint extends Point
function ColoredPoint(x, y, color) {
// call the "super constructor"
Point.call(this, x, y);
this.color = color;
}
// We use a clone of Point.prototype as the extension prototype
ColoredPoint.prototype = Object.create(Point.prototype);
// we extend Point with the show method
ColoredPoint.prototype.show = function () {
console.log('Point with color ' + this.color + ' at (' + this.x + ',' + this.y + ')');
}
// finally we can use colored points:
var p = new ColoredPoint(10, 20, 'red');
console.log(p.distanceFromOrigin());
p.show();
As you can see it’s possible to do single inheritance, but there are a lot of required steps. That’s why there are so many JavaScript libraries to simplify the definition of objects.
In a next post I’ll share my experiences on creating barman (one of the many JavaScript object definition libraries that are out there). And I’ll use that experience to discuss some “advanced” techniques to share behavior like mixins, and traits.