
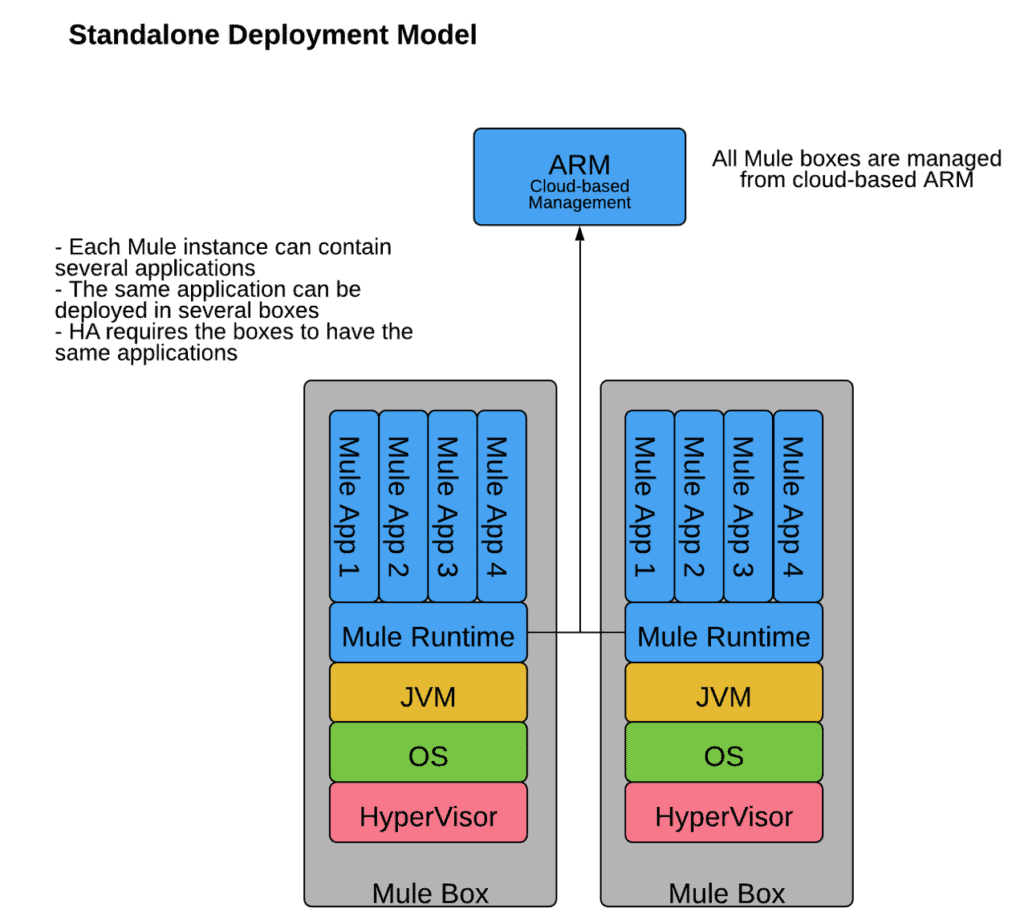
Standalone Mule runtime engine allows customers to deploy applications in their server, located in the cloud or data center. All application data remains within the customer network so it is a choice for security conscience customers who may have regulatory needs or security policies to comply with.
However, as the customer’s application network grows they may face various challenges with a standalone architecture:
- Since all applications deployed into a standalone server share memory and CPU, any rogue applications can cause the server to go down and impact other applications on the same server.
- A standalone Mule runtime engine can’t be shared across customer’s various business groups.
- The standalone architecture can only allow for one Mule runtime version — making upgrading versions a challenge in situations where customers want to utilize new features.
Our new deployment model for Runtime Fabric — built on Docker and Kubernetes — has been the preferred choice for many of our large customers who are trying to mitigate the above concerns with a standalone Mule runtime engine to comply with the internal deployment standardization. Some key advantages of Runtime Fabric:
- Increased reliability through isolation between the applications
- Zero-downtime application re-deployments
- Ability to share Runtime Fabric clusters across business groups
- Containerized Mule runtimes are managed/updated automatically by using the control plane
- Log forwarding comes bundled in with Runtime Fabric
With our field knowledge, we have seen multiple customers successfully migrate from on-premises standalone Mule runtimes to Runtime Fabric. Below are some guidelines to help on your migration journey to Runtime Fabric.
Skillset required to support Runtime Fabric
Although Runtime Fabric is provided to customers as an appliance, we found that fundamentals of Linux, Docker, and Kubernetes are a must to support Runtime Fabric clusters. When troubleshooting Runtime Fabric issues, some commonly used Kubernetes and gravitational commands will come in handy. We recommend the operations teams that maintains Runtime Fabric environments also design, implement, and architect production-level Runtime Fabric clusters. Also, invest in getting certified in the underlying technologies, such as Kubernetes, MuleSoft Certified Platform Architect, and Linux administration.
Sharing Runtime Fabric with business groups and associate environments
Before you install Runtime Fabric cluster, you will need to determine which level in the organization structure Runtime Fabric will be created. When you are creating a Runtime Fabric cluster, you can create them at any level of the organization structure. If you choose to create the cluster at the master-org level it will allow you to share the cores in Runtime Fabric with the business group created under the master organization. Runtime Fabric cluster can be shared vertically down in Anypoint Platform, but not across. Runtime Fabric cluster inherited in the child group will have all the settings in read-only mode. Some of the common scenarios are mentioned below:
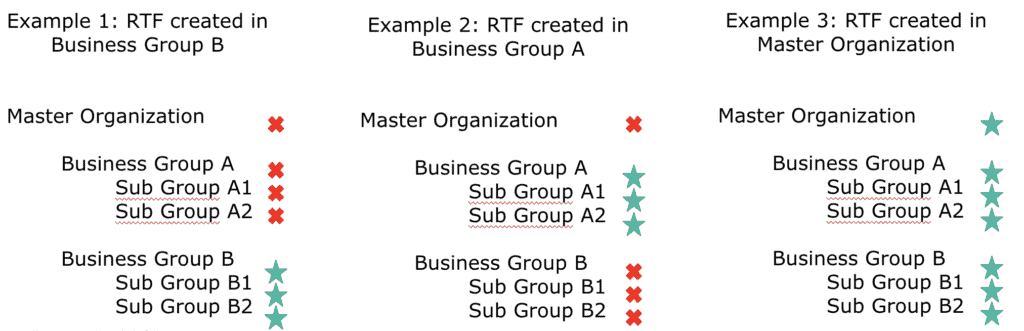
Some customers want to govern the number of cores used by a line of business (LOB). In those cases, we recommend you create Runtime Fabric cluster at the business group level of the LOB. In this setup, you will incur additional infrastructure costs to setup controller and worker nodes for each LOB, but you will be able to allocate part of the cores to a LOB to create a chargeback model. Each LOB should be capable to support operations for Runtime Fabric cluster.
Some of the known Runtime Fabric limitations are mentioned here.
Installing Runtime Fabric
Before you begin installing Runtime Fabric, take a look at the prerequisites. Verify all the ports connectivity following this article. Currently, we provide installation templates for AWS, Azure. Customers can also opt for manual installation for bare metal servers and VMs.
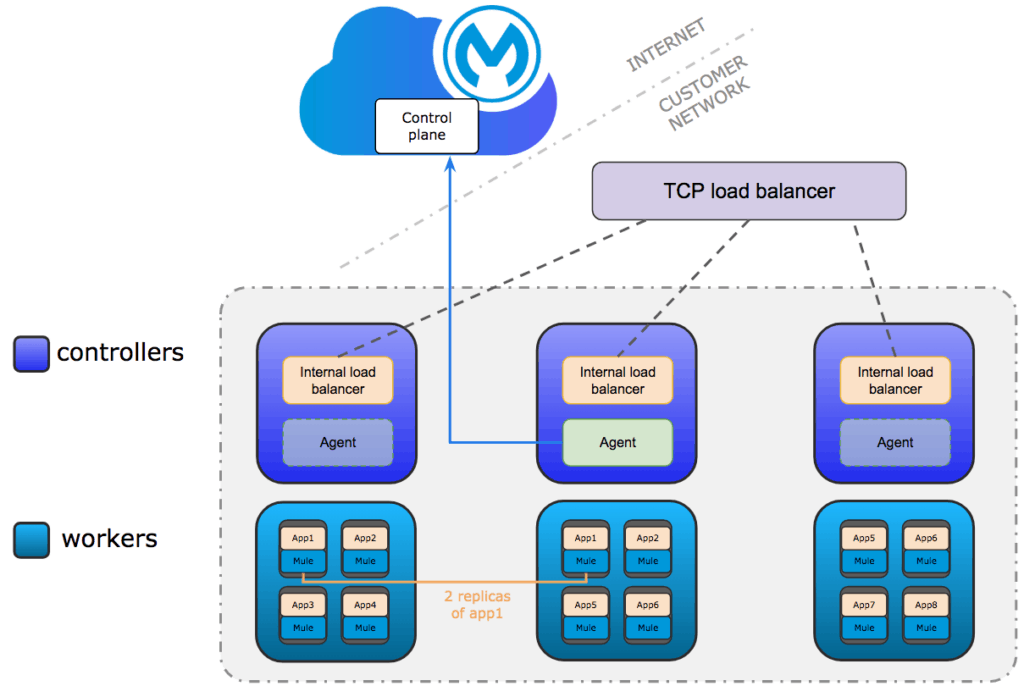
For a production setup, the minimum recommended configuration is three controllers and three workers nodes. This is necessary to achieve fault tolerance and high availability. An external layer four TCP load balancer (Eg: F5, NGINX) will be required to pass the traffic to the internal load balancers. When you setup a Runtime Fabric cluster, add additional capacity (vCPU, Memory, etc.) to the workers. This will ensure that you have enough headroom for node failures. Eg: one out of three worker nodes fails, the workloads running on that failed node need to be rescheduled (evacuated) to the remaining two nodes — so in three worker clusters the workers’ optimal workload is around 50~60%.
For a development and sizing setup, the minimum configuration is one controller and two worker nodes. Setup at-least one staging environment which will be a replica of production to perform performance testing and user acceptance testing.
Secrets manger with Runtime Fabric
Anypoint Security secrets manager uses secure vault technology to store and control access to certificates. In Runtime Fabric, to enable the inbound traffic for an incoming request you will need to add the CA certificate in Runtime Manager Runtime Fabric configuration. You can store TLS artifacts in the secrets manager and then configure Anypoint Runtime Fabric inbound traffic configurations using the TLS context from secrets manager. When you are creating a certificate for Ingress, a common name (to which the certificate applies) must be specified. You have two options:
- Using a wildcard (e.g. *.OrgDomain.com) in your cname, so your application URLs will use the following format:
- {app-name}.OrgDomain.com
- If you don’t use a wildcard, it will be this format:
To setup, the TLS context in secrets manager follow the steps mentioned here. To enable the inbound traffic in Runtime Fabric, follow this article.
Disaster recovery and high availability
To achieve high availability in standalone deployments in cluster mode, you need an external load balancer like F5 to distribute traffic between MuleSoft servers. Standalone servers use clusters to recover from server failures by synchronizing statuses. HA in Runtime Fabric is achieved by creating replicas for an application across multiple workers. During deployment you can force application replicas to deploy into separate worker nodes. Runtime Fabric is self-healing; in a scenario where a worker node goes down, Runtime Fabric agent will try to create an application replica inside an available worker node to keep the number of replicas the same as the number which the user provided during deployment.
Various complications can cause a Runtime Fabric cluster to go down. You need a disaster recovery strategy to deal with these circumstances. The disaster recovery strategy on Runtime Fabric depends on the client’s RPO (recovery point objective) and RTO (recovery time objective) requirements. There are two popular disaster recovery strategy that our customers use:
- Active/Passive: Production and DR deployed in two different data centers (AZs)
- Set up a DR (second) cluster with similar specs in a different physical location.
- Any deployment will be deployed to active and passive clusters. The passive DR cluster will be stopped. A passive DR cluster needs to start in case of a disaster and the external load balancer will switch all traffic to the DR cluster. So you should account for startup time in your disaster recovery strategy.
- Active/Active: To achieve zero downtime in case of disaster, active/active would be the strategy, where a load balancer can route the traffic to each datacenter and in case one of the data centers (AZ) goes down, the load balancer will send traffic to the active datacenter (AZ).
Developing application for Runtime Fabric
- Shared resources: Runtime Fabric does not support the usage of domain shared resources. Runtime Fabric’s architecture ensures that there is always one application deployed to a dedicated single Mule Runtime pod. If your on-premises application has a domain project with shared configs, you will need to refactor these configurations and have local configs for each application in Runtime Fabric. For example: HTTP/HTTPS listeners, DB configuration, etc.
- Ports for the HTTP listener are same for Runtime fabric applications. Mule apps deployed in Runtime Fabric must listen on host 0.0.0.0 and HTTP/HTTPS port (8081) .
- In some scenarios, sharing the application logic in Runtime Fabric may be required — for example, error handling, logging, notifications. You can achieve this by creating a separate project packaged as a jar. This project can be added as a dependency using a dependency management tool, such as Maven.
- JVM Tuning is limited for Runtime Fabric pods. Each pod that is provisioned for a replica will come with a wrapper.conf which defaults the JVM parameters to preconfigured values. Usually, 50% of the memory provisioned for the Runtime Fabric application is allotted for Heap memory.
- Modify the pom.xml to change the dependencies for Runtime Fabric. Eg: Mule Maven plugin modify for Runtime Fabric. If using the Maven plugin to deploy then, make sure the application group id is the same as the exchange org id.
- DataWeave transformation logic in the existing on-premises applications can be reused in Runtime Fabric applications.
- End-to-end application-level mutual TLS is not supported out-of-the-box (OOTB). Mutual TLS termination happens at the internal load balancer/edge.
- To enable TLS communication from the edge(internal load balancer)→Mule application, enable the last mile security.
- Application deployed to Runtime Fabric communicates over port 443 using the https protocol. If a user tries to call application over port 80 it is automatically redirected to port 443.
- Customers who don’t want the URL changes to affect the client application calling the on-prem API in Runtime Fabric can add another Layer 7 load balancer to rewrite the URL. Eg: add an ALB to rewrite the application URI.
- Make changes to the applications that use connectors that are not supported in Runtime Fabric. For example, the File Connector can be replaced with the SFTP connector.
- Runtime Fabric clustering works differently than standalone clusters. Persistent object store is not available in Runtime Fabric since restarting the application will cause the deletion of the existing object store. Make changes to your applications to replace persistent object stores with external Caching provider like Redis Cache as a custom object store.
- Currently, in Runtime Manager for Runtime Fabric, you cannot hide the property value. When you need to secure the secret values in a Mule application use the secure configuration properties and store the mule key in the Runtime Fabric Cluster locally.
- In on-prem standalone runtimes, edge-level protection is not available OOTB. Customers opt for third-party tools and software’s to meet the security and network requirements. Runtime Fabric gives you the capability to apply policies such as denial-of-service (DoS), IP allowed-list, HTTP limits, and Web Application Firewall (WAF) policies at the edge. Anypoint Security policies act as a default firewall/router capability through which all traffic traverses. This is not available for standalone servers.
- Tokenization service is one of the most requested features from our banking customers which is available with Anypoint Security. Here are the prerequisites for using the Tokenization service with Runtime Fabric. Tokenization service supports a variety of data domains.
Sizing Runtime Fabric application
In standalone runtime all applications share the server resources (vCPU and memory). However, Runtime Fabric has a containerized model where each application gets vCPU and memory based on allocated size. When a Mule application is deployed to Runtime Fabric, the application is deployed with its own Mule runtime engine. The number of replicas, or instances of that application and runtime, are also specified. The resources available for each replica are determined by the values you set when deploying an application. We recommend customers to deploy up-to ~25 mule applications or API proxies per vCPU. In this documentation you will find the parameters that you will need to define when deploying Runtime Fabric.
When you select same value for both reserved vCPU and vCPU limit then the application is allocated cores in a guaranteed model. When the vCPU limit is set higher than reserved vCPU the application can burst up to vCPU limit or idle vCPU whichever is less.
Sizing is based on the the following factors:
- Number of APIs / applications
- Number of calls
- Applications’ type of workloads
- HA factor / replica per application (2+ for production)
- Performance benchmarking for Runtime Fabric
- Factor in the reserved CPU for Runtime Fabric inbuilt services
- As bursting apps compete for unallocated CPU:
- Deploy batch applications that run nightly with API that have peak load during the day.
- Deploy multiple replicas of an API to distribute across worker nodes and maximize burst-able surface area.
Change your CICD to new deployment model
When migrating the application to Runtime Fabric, you will need to tweak the CICD pipelines to support the Runtime Fabric deployments. Runtime Fabric has some additional steps to upload deployment jar in Exchange. Before a MuleSoft application can be deployed into Runtime Fabric, the deployable jar should be uploaded to Anypoint Exchange. Anypoint Exchange acts as an artifact repository for MuleSoft applications. You should make sure that no other artifact with the same artifact ID as the MuleSoft application name exists inside Anypoint Exchange with a different artifact type or else it will return an error. Multiple versions of the deployment jar in Exchange helps you with rollback and rolling updates. MuleSoft application jar can be published into Exchange using:
- Anypoint Studio
- Manually
- Maven plugin
- Anypoint Platform APIs
Currently, Runtime Fabric does not support Anypoint CLI. Please find the Postman collection for the deployment of Runtime Fabric application using the Anypoint Platform APIs.
Monitoring changes for Runtime Fabric
In a standalone setup, you may have monitoring agents (eg: App Dynamics, Data Dog) installed on the servers for an end-to-end monitoring. When you migrate to Runtime Fabric, monitoring tools other than Anypoint Monitoring are not supported. To monitor the health of a cluster, you can use the built-in ops center. You can use the ops center to monitor the dashboard, view logs, and monitor debugging information. To monitor the health of the controllers and workers, you can also use some of the native cloud technologies — such as the CloudWatch for AWS or install external agents on the servers, such as DataDog or AppDynamics( Cannot monitor pods).
Alerts in Runtime Fabric are setup in Ops center. Ops center uses Kapacitor formulas to send built-in alerts to the email address configured. You can modify the contents of the alerts sent to the email.
Logging considerations in Runtime Fabric
If the on-premises system has any log aggregation agents installed, like SPLUNK or ELK, you will need to change the strategy as agents cannot be installed into the running app/Mule runtime container, nor can sidecar container be created as we cannot change the container orchestration process in Runtime Fabric. You can forward the logs to external, service such as Cloudwatch, Azure log, SPLUNK, etc.
You can disable or enable log forwarding per application in Runtime Fabric. Shared log4j.xml for multiple Mule applications on-prem is not supported in Runtime Fabric. Each Runtime Fabric application will need to package a custom log4j.xml with appenders added for the external logging system if needed. If you have to change the log levels using the runtime manager UI or Properties, on-prem has a logging tab in Runtime Manger which will allow you to change the logging levels of different packages (Eg: HTTP). If you need to change the log levels you will have to use the properties tab with logging.level syntax to change the log level of packages.
Summary
In this blog post, we covered the migration steps that you will need to consider when moving from a standalone on-prem setup to Runtime Fabric. Runtime Fabric also supports Mule 3.x runtimes but to reduce technical debt consider this as an opportunity to move your Mule 3 applications to Mule 4 on Runtime Fabric. In the next blog, we will discuss the migration steps for CloudHub to Runtime Fabric.
To learn more about Runtime Fabric, take our Anypoint Platform Operations: Runtime Fabric course. If you would need help with the migration implementation, contact MuleSoft Professional Services or a MuleSoft Partner.



