
The recent release of Anypoint Runtime Fabric to the managed container platforms offered by Amazon Web Services, Microsoft Azure, and Google Cloud Platform opens the door to a range of new deployment architectures that would have previously been cost prohibitive.
With the “bring your own kubernetes” approach you no longer need to explicitly provision and operate dedicated infrastructure for controller nodes. This is provided as part of the managed K8s offering from AWS, Azure, or GCP. With BYO-K8s you only manage compute and storage for worker nodes. This makes it easier and cheaper to spread workloads across different regions without having to budget for duplicated overhead expenditure.
In the first post of this two-part series, we’ll look at building a highly-available Runtime Fabric instance and how that is enhanced with a multi-region approach. We’ll then see how that would be constructed in practice using a simple DNS-based approach. In the second part, we will discuss a more evolved approach that uses a dynamic content distribution system to route incoming traffic.
Location and routing considerations
So you’ve decided that we want to have multi-region availability to provide maximum fault tolerance. Before you do this though, you should consider the rest of our architecture. Where will your users be accessing our APIs from? Where do your client applications run? Where are your backends?
We must remain mindful of latency and the impact on user experience. A point of best practice is that outward-facing APIs should reside as close to the clients as possible. That way you get the lowest possible latency between the client and the API. Any upstream latency will fall within the bounds of Anypoint Monitoring that allows us to easily monitor and alert on unexpected changes or poor response times. If all our users and clients are located in North America, we probably don’t want to have integration workloads located in Asia-Pacific, for example.
When deploying across multiple regions for high availability we should stick with regions that are still within the same continent or within a reasonable distance from each other (e.g., eu-west-1 & eu-west-2, or us-east-1 & us-east-2). This is particularly important in active-active configurations where a user request may be dynamically served from either region. We don’t want some requests to be routed fully within the EU, whilst others get routed from the EU, to the USA, and back to the EU, for example. That would cause variations in end-to-end response time that would at best be unpredictable and at worst could cause race conditions or other data consistency errors.
We should also consider where our backend services are hosted and how these relate to our integrations and APIs. Do we route our integration applications to backends in the same region, cross-region, or balanced between the two? For HA purposes, clearly we don’t want to have services running in one region that are fully dependent on another, as that achieves nothing. We also need to consider application state, as we do not want a customer to start a session in one location and then attempt to continue it in another region unless they are synchronized.
In our examples here, we will host our services across eu-west-1 (Dublin) and eu-west-2 (London) regions, which would be a good choice for spreading European-based workloads.
A basic highly-available architecture
We will set up our instances of Anypoint Runtime Fabric in our chosen AWS regions, using Amazon Elastic Kubernetes Services (EKS). We won’t cover the actual installation of Runtime Fabric on EKS here; more information on that is available in the MuleSoft Product Documentation pages, but the overall deployment within a single region might look like the following architecture:
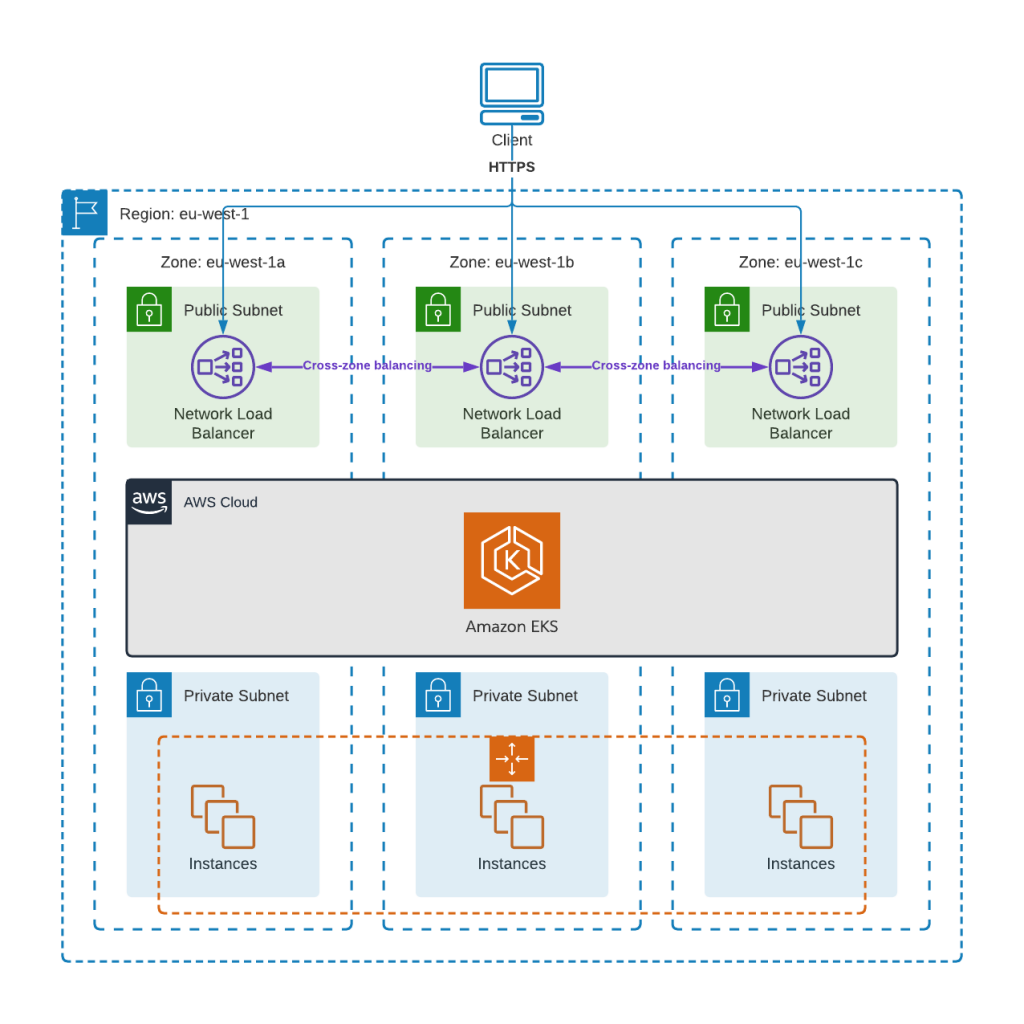
For maximum availability, we create the EKS cluster across multiple Availability Zones (AZs) in the region to protect against single-site failures. We configure the cluster using an auto scaling group (ASG) that maintains a set of nodes appropriately sized for our workloads. If a node in the ASG fails, a replacement node will be provisioned and added to the cluster for us — an auto-scaling feature of Anypoint Runtime Fabric.
The ASG is attached to an elastic load balancing target group that is automatically updated with new nodes that get brought into or removed from the ASG. Each AZ contains a Network Load Balancer (NLB) that forwards HTTPS traffic to nodes in the ASG. Each NLB has “cross-zone balancing” enabled, which allows a NLB to spread traffic across all nodes in all AZs.
When our client needs to request our application it will perform a DNS lookup that resolves to one of the NLB instances using an appropriate algorithm (most likely a simple round-robin). The client then sends its request to that NLB that in turn forwards it to the Kubernetes ingress running in our node group.
This approach already gives us a good amount of availability as workloads and network paths are spread across multiple AZs (that represent multiple physical data centers). Any node failures should be automatically detected and a replacement node added to the pool. This gives us coverage for normal day-to-day availability concerns, such as adding and removing nodes from the cluster for patching or upgrades. When we combine this with Runtime Fabric deployments using multiple replicas, we can host our integration applications in a highly-available way.
While the approach above is good, it still has a single point of failure at AWS region level. Although highly unlikely, it is possible that a whole AWS region is impacted by a major outage. For the most critical applications, it may be necessary to have additional resiliency by introducing a secondary AWS region.
Let’s look at how we can add multi-region support to our Anypoint Runtime Fabric environment.
Multi-region using DNS
One simple, but effective approach would be to simply deploy a secondary fabric to another region and use Amazon Route 53 to spread traffic between the two regions. Route 53 provides a number of advanced resolution capabilities that allow traffic to be intelligently routed based on weights, latency, geolocation, health checks, etc. Further information on Route 53 capabilities can be found on the Amazon Route 53 website.

Unlike in CloudHub, application names in Runtime Fabric do not need to be globally unique — they only need to be unique at the fabric level. This means each of our fabrics, in each region, can host identically named applications. This makes application routing across both fabrics very simple as we can send the same request to either fabric. Both fabrics’ ingress will need to be configured using the same TLS context (private key and certificate) however, as the request headers sent by the client will not distinguish between the different regions.
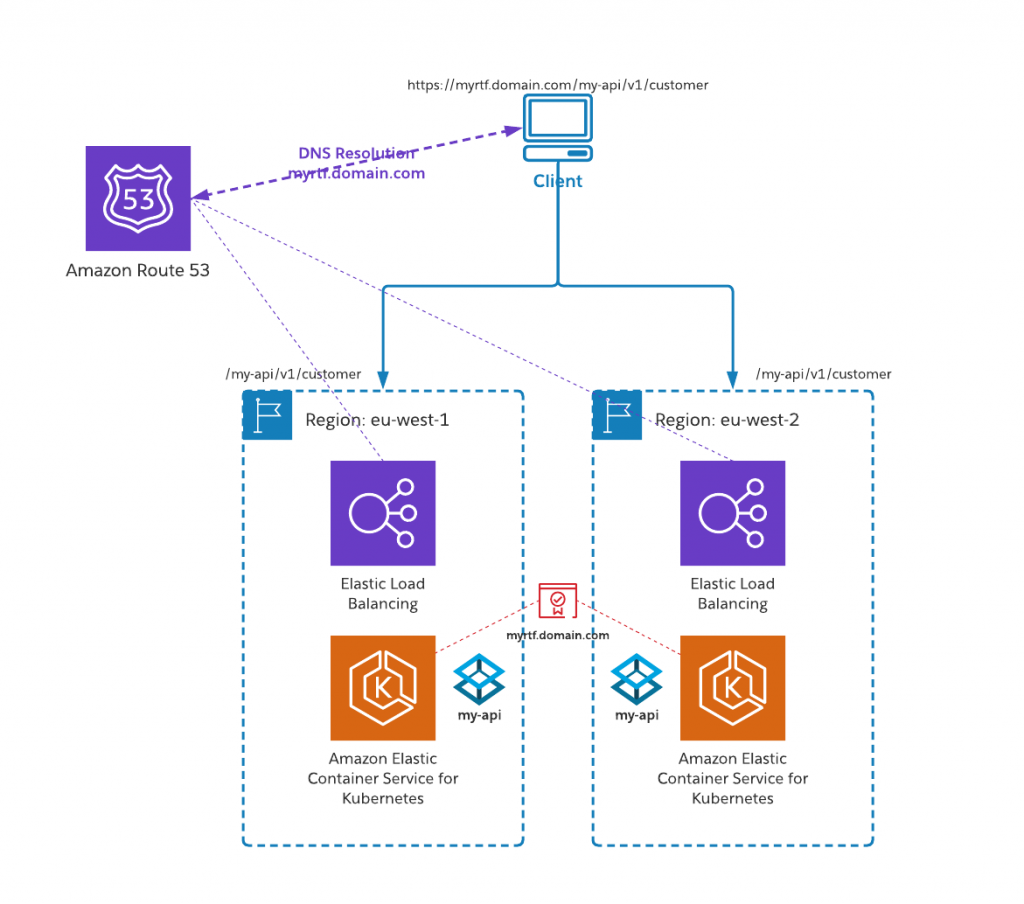
We simply deploy our Mule application to both fabrics as normal in an active-active configuration — remembering to consider upstream routing as discussed above. It may be necessary to have separate property configurations for each region to manage backend endpoints, authentication, etc.
This gives a simple yet highly effective and reliable way to distribute workloads transparently across multiple regions that doesn’t require additional significant components in our architecture.
In this post we’ve discussed the importance of deploying a highly-available Anypoint Runtime Fabric instance and how to do this across cloud regions for increased resilience. We showed a simple implementation using a global DNS service. For the next part in this series, I’ll show an alternate multi-region architecture that uses Amazon CloudFront for a more dynamic experience.
Learn more about the various Anypoint Platform deployment models by watching our webinar.



