Reading Time: 11 minutes
This is part five of the API design best practices series.
Design is Important, But…
Over the last several weeks we’ve looked at the design aspect of building APIs. We’ve covered planning out your API, spec driven development, and best practices. But your API is really a vehicle for developers to access data and services, much like a plane is a vehicle for transporting people to and from places. But building the plane isn’t enough, along with having the actual vehicle, you need airports with checkpoints to make sure that only the people who are supposed to be getting in that plane have access, and likewise that no one is trying to do anything malicious.
The hidden danger of an API is that it can expose vulnerabilities within your application. Both accidental and malicious abuse of your API can hammer your servers causing downtime for you and your customers. And often times, this is as simple as an inexperienced developer (or even an experienced one) throwing in an infinite loop.
Authentication is Key
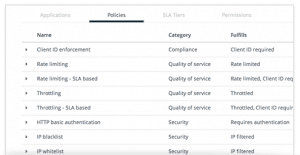
By providing your API users with a unique API token, or API key you can tell exactly who is making calls to your API. Along with having quick access to determining potential malicious users which can immediately be removed, you can also set permissions and SLAs for users depending on their individual needs. This means that you can set a default SLA for most users, giving them say only 4 calls per second, but for silver partners they get 10 calls per second, for gold partners 100 calls per second, etc. This means that you can not only identify abuse quickly, but also help prevent it by limiting their access to certain aspects of your API, and by limiting the number of calls they can make to your API.
Throttling Isn’t Bad
Throttling and rate limiting isn’t a bad thing. Again, by throttling your API and setting up different SLA tiers you are able to help prevent abuse – often times completely accidental. This means that your API is able to operate optimally for all of your users, instead of having one infinite loop bring it crashing down for everyone.
And yes, you may have partners that need more calls than others, or who the limits do not make sense for. But again, by setting up SLA tiers based on your standard API user’s needs, and then creating partner tiers, you can easily give the the permissions they need, while limiting the standard user to prevent abuse.
The API key, or unique identifier for an user’s application also helps you identify who your heavier users are – letting you get in contact with them to make sure their needs are being met, while also learning more about how they are using your API.
Security. Security. Security.
An API Manager should also be designed to handle security, not just by validating a boarding pass (API key) and directing them to their appropriate gate (permissions, SLA tier), but your API Manager should watch out for other dangerous threats, such as malicious IPs, DDoS, content threats (such as with JSON or XML), and others.
It should also be designed to work with your current user validation systems such as OAuth2 to help protect your user’s sensitive data (such as their username and password) within your API. Keep in mind that even the most righteous of applications are still prone to being hacked – and if they have access to your user’s sensitive data, that means that hackers might get access to it too. It’s always better to never have your users expose their credentials through the API (such as with basic auth) but instead rely on your website to handle logins and then return back an access token as OAuth2 does.
But… Security is Hard
One of my favorite talks, by Anthony Ferrara sums this up very nicely… Don’t do it. Leave it for the Experts. Granted, his talk was specifically on encryption, but there’s a lot of careful thought, planning, and considerations that need to be taken when building an API Management tool. You can certainly build it yourself, and handling API keys or doing IP white-listing/ black-listing is fairly easy to do. However, like an airport, what you don’t see is all of the stuff happening in the background, all the things being monitored carefully, security measures implemented by experts with years of experience in risk mitigation.
For that reason, as tempting as it might be to build one yourself, I would strongly encourage you to take a look at a professional API Management company- such as MuleSoft (of course, I might be a little biased).
Expensive… but Incredibly Cheap
It’s very easy to look at an API Manager’s price tag and have a little bit of sticker shock. However, it’s important to understand that when it comes to security, you can either pay up front- or much more down the road. By having a proxied API Manager you have a tool that can prevent malicious attacks from reaching your server, helping keep your network, architecture, and user data safe. After all, the average cost of a breach in personal data is 5.5 million – unless you’re a much larger company like Sony, and then you’re looking at 172 million, a price tag that makes even the most expensive API Manager well worth it.
Along with the security factor, building an API Manager takes a substantial amount of time, and maintenance. Even without considering the need for multiple security experts to help ensure you are mitigating malicious attacks on your API, you may find that the investment to build, and maintain even the simplest of API Management solutions quickly adds up, and will most likely exceed the cost of using a pre-existing service.
Click to Learn More about MuleSoft’s API Management Solution
Next week we’ll review: