In this final part of our introduction to DataWeave, we now present you with some example transformations. Just in case you missed the previous posts I included parts 1 to 3 below:
We will use everything we have learned till now to realize the transformations. Wherever we introduce new concepts we will highlight them in a subsequent set of notes. So, without further delay, let’s jump in!
Scenario 1
Google’s Address API responds with a JSON object which contains an array of addresses followed by their distances from our current location. We want to transform this into an array of the top 5 closest addresses.
Input
Output
Transformation
Notes
The flatten operator transforms an array of arrays to a single array containing all of the elements in each of the nested arrays.
$$ is an alias for the the index of the current iteration through a.
d[$$] selects the element in d whose index is $$. Dynamic key selection will also work on objects. Any expression which resolves to the name of the key can be used within square brackets.
Scenario 2
Given an Xml document with a sequence of line items, transform it to a JSON document with the field names slightly modified.
Input
Output
Transformation
Notes
‘$$_1’ allows us to dynamically build the value for the keys in our output by appending ‘_1’ to the key name present in the input.
mapObject is an operator that iterates through the key:value pairs on the input Value object and rather than produce an array, it simply builds another object defined by its right-hand operand.
Scenario 3
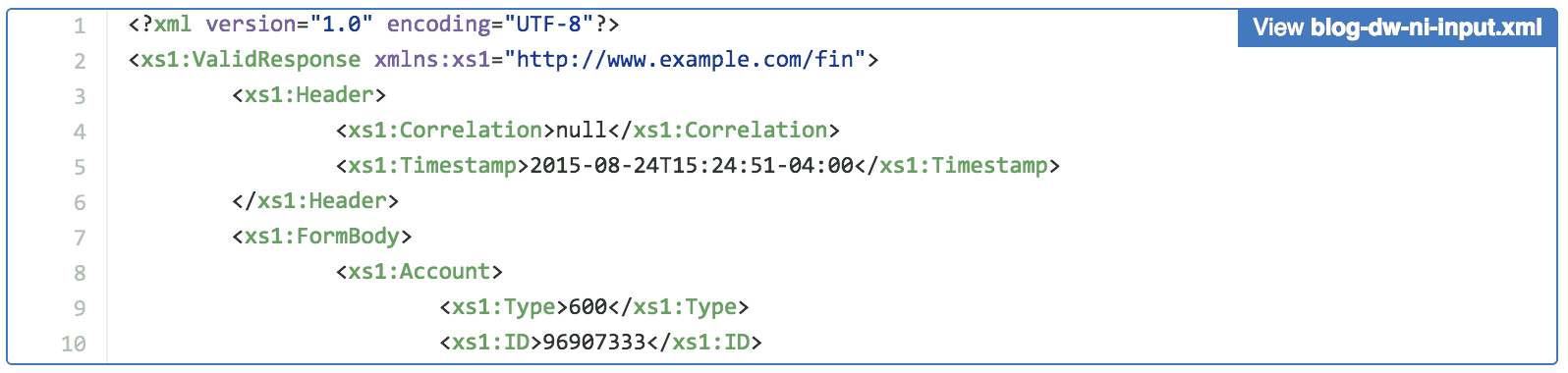
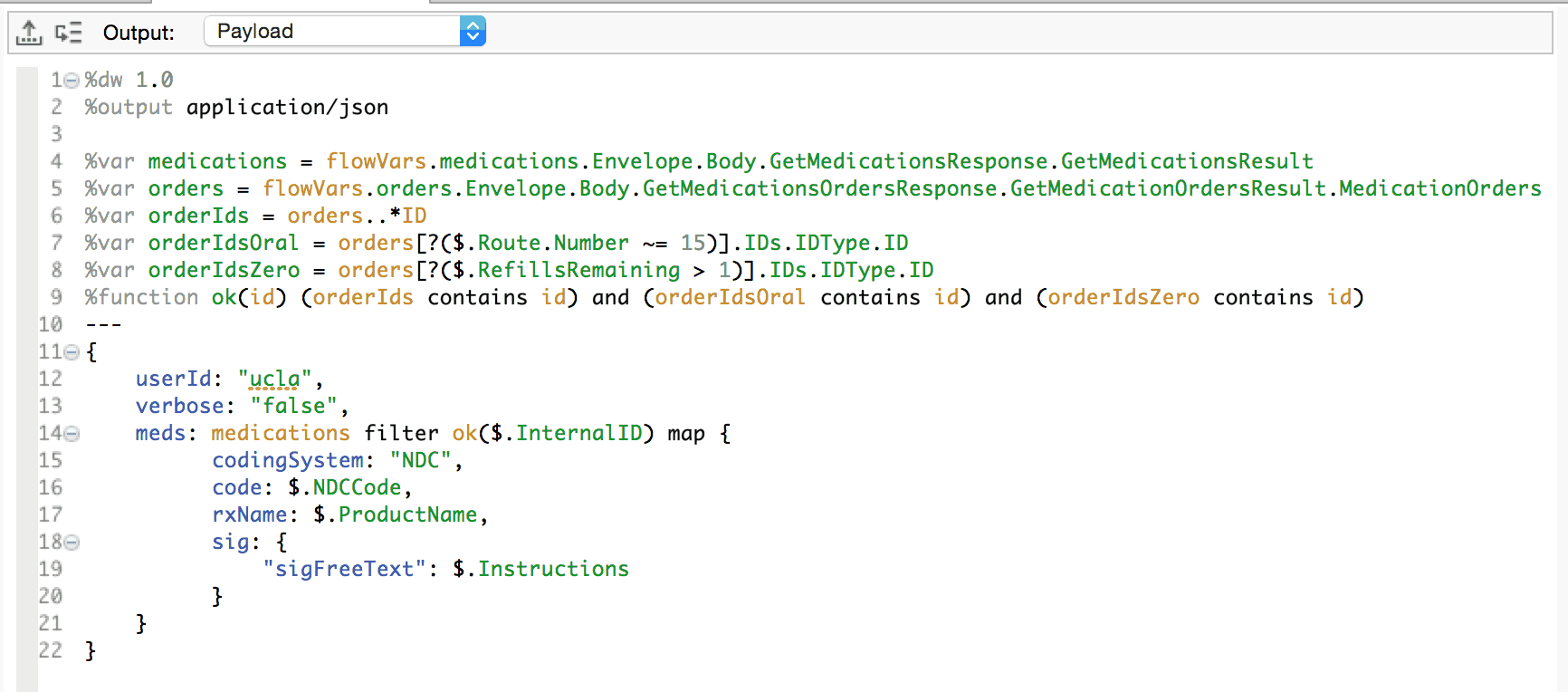
Given 2 responses to SOAP-based WebServices as input transform them into JSON object. The first Xml GetMedicationsResponse contains the medications for a patient. The second Xml GetMedicationsOrderResponse contains orders for the same medications. We need to iterate through each Medication in the first Xml and only produce output if the InternalId for the Medication is in the list of Orders and they Route code for the Order is oral (15) and the RefillsRemaining on the Order is greater than 1.
Input
Output
Transformation
Notes
The %var global variable declaration allows us to use those variables anywhere in the transformation, including other global variable value assignments and function bodies.
The [?(<filter-criteria>)] expression allows us to filter on a key selector. There is a subtle difference between this mode of filtering and that of the filter operator. When no elements on the array match the criteria in this construct, then null is returned. Filter on the contrary will return an empty array.
The contains operator tests for the presence of a value in a container. The right-hand operand is the value. The left-hand operand is the container. This can be an array, a string or an object. When objects are tested, the container is actually the array of values in its sequence of key:value pairs. Here, we simply test arrays of strings for the presence of a string.
Scenario 4
Given a plain text sequence of identifiers, separated by the character ‘+’, and each of which may begin with a code containing 2 to 4 upper-case letters, output a JSON object whose keys are those same codes and whose values are arrays of the remaining part of each identifier which begins with the code. If any identifiers are found that don’t contain codes as specified, then these should be added to the array keyed by ‘invalid’ in the output.
Input
Output
Transformation
Notes
The splitBy operator creates an array of the values resulting from those sequences of characters between each occurance of the splitting criteria specified as its right hand operand.
The match operator returns an array of matches that contains the entire matching expression, followed by all of the capture groups that match the provided regular expression. In this case ($ match /([A-Z]{2,4})d*/)[1] will return the code which will be in the first and only capture group for those identifiers it matches.
The default operator returns its right hand operand value when its left-hand operand returns null.
The pluck operator iterates through the key:value pairs on an object and builds an array of its values ($) or its keys ($$).
Scenario 5
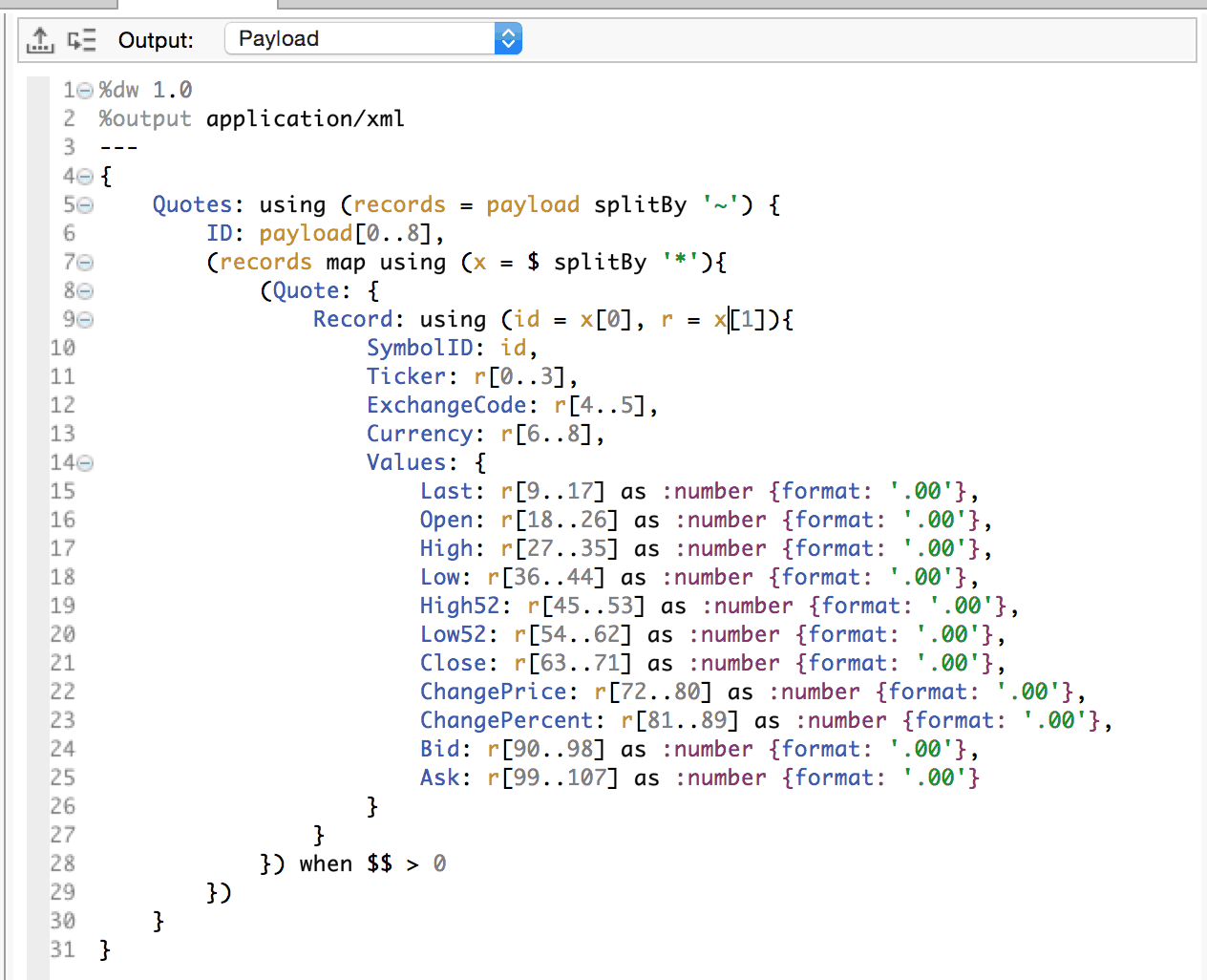
Given an Xml document containing Stock quotes, transform it into a plain text sequence of characters with the <Values/> elements padded to 4 digits before and after the decimal, separating each Quote with a ‘~’ and terminating the SymbolId with a ‘*’.
Input
Output
Transformation
Notes
The reduce operator iterates through an array and executes the lamda function you define as its right-hand operand. In this case we append each element quote to the accumulator qStr.
Scenario 6
Take the output from Scenario 6, the plain text string of codes and values and transform it back to the original input Xml from Scenario 5.
Input
Output
Transformation
Notes
Here we necessarily cast each of the values to a number with two decimal places using the as operator. Thus we remove the padding zeros leading and trailing each value.
Further Reference
That’s it! We refer you to our documentation for an deep reference of the complete language as well as a tutorial to help you get started and a webinar with more a live demonstration and finally, some more examples.
Reading Time: 5minutesIf you’re a Mule user, there’s a good chance that you’re using Maven to automate building and testing of your applications. We’re happy to announce Mule Maven Plugin 2.0, to help you automate your deployment and integration tests. This plugin will help you no matter where do you want it to run: CloudHub, a local Standalone server, Anypoint Runtime Manager, a local cluster or using the Mule Agent.
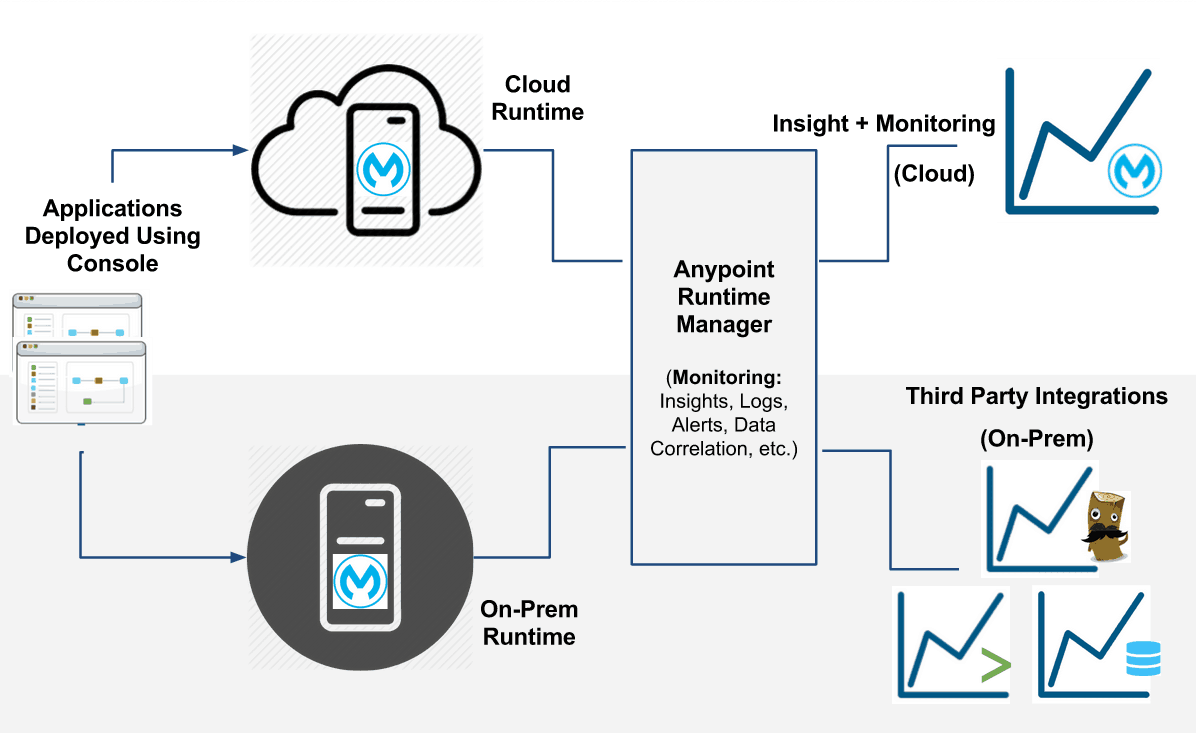
The August 2015 Update 2 of Anypoint Platform features v1.2 of Anypoint Runtime Manager which enables users to monitor and analyze applications running in the cloud or on-premises, in a sandbox, staging or production environment with ease using popular monitoring tools like Splunk and ELK. This gives the users a unified view of all their applications, no matter where they are running.
Monitoring/analytics for On-Prem users
Users of Anypoint Platform – iPaaS have been able to leverage Insight (business events), logs, alerts, messaging, etc to monitor their applications. With this release, on-prem users can leverage similar features and functionality by integrating with third party monitoring tools. This can be done seamlessly with our brand new out of the box Plugins for Splunk & ELK, which simplifies the experience. Users can send vital event notifications such as business events and API metrics, to a system of their choice, which enables them to have a unified monitoring view of their systems.
The purpose of this demo is to display how you can configure and use your third party integration systems, such as Splunk and ELK, with ease. In the examples below we will step through how to integrate with Splunk and create visualizations for a custom business transaction or event.
Integrating with MuleSoft Plugin for Splunk MuleSoft enables users to seamlessly integrate into their Splunk instances, using our Splunk plug-in, in 2 easy steps.
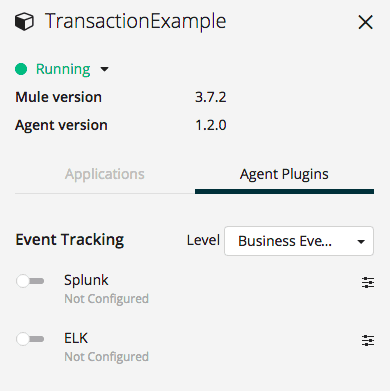
Step 1: Login to your Anypoint Platform account and click on a server that you’d like to configure. The server will need to be up and running and have a deployed application.
Step 2: Enable Splunk, enter your credentials, and click apply.
The video below steps through how to integrate your system in Splunk and test a transaction.
Tracking Custom Business Events on Splunk
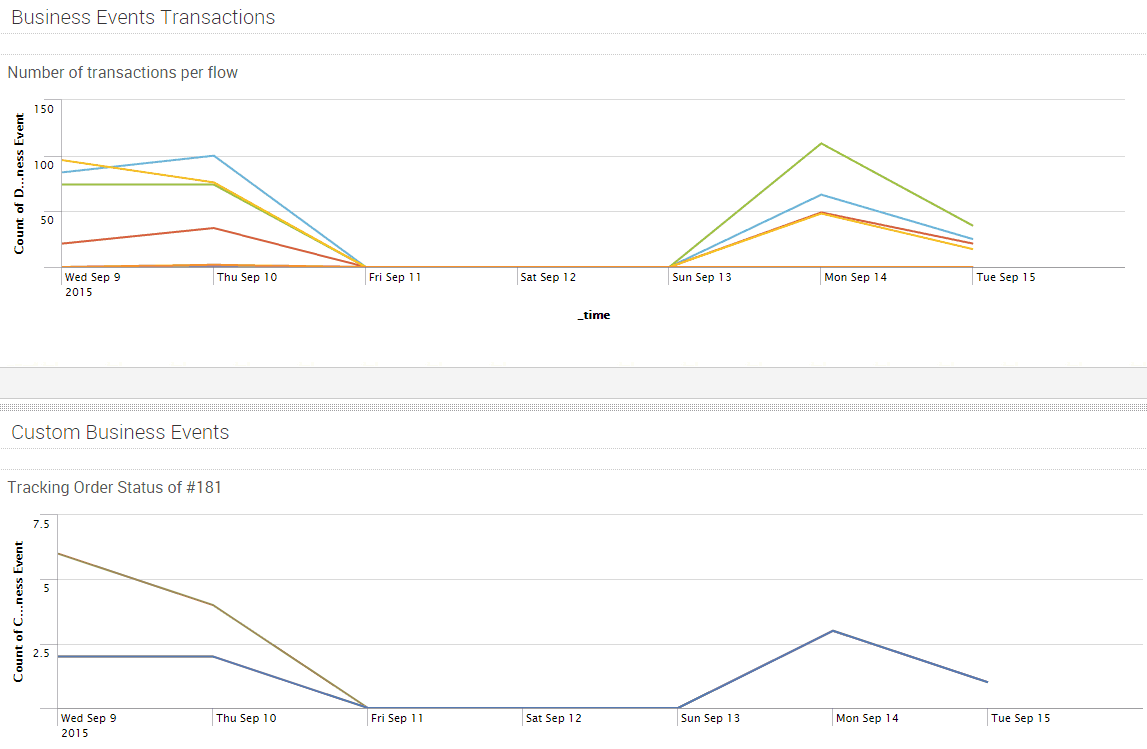
Once the user configures their system for Splunk in Anypoint Runtime Manager, messages from an on-premises Mule runtime will start populating in Splunk. The user has the flexibility to generate reports, create standard and custom dashboards, track business events, etc. In the screenshot below, the first graph shows a visualization of the number of transactions/business events generated per each custom Mule flow created by the customer. The graph below it demonstrates the ability to pick a specific transaction and monitor its path.
For more information and examples check out the links posted below:
Documentation Links: Click here for documentation on using the product. Click here for release notes.
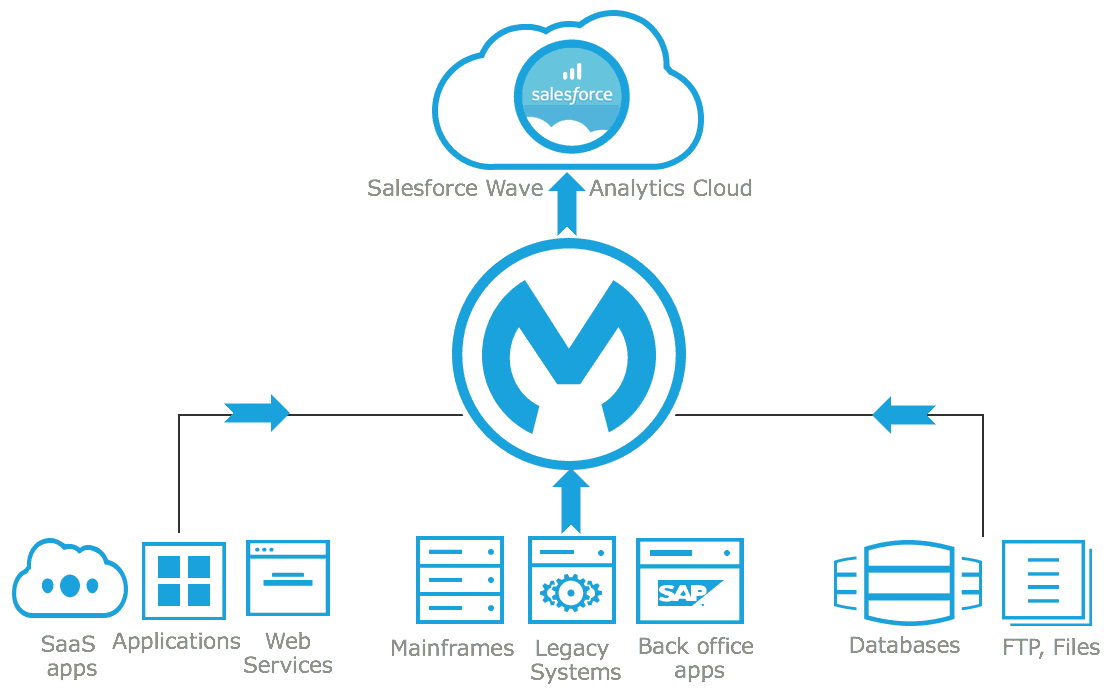
We are happy to announce the September ’15 release of the Salesforce Analytics Cloud Connector v2.0.0. In this blog post, I will be covering some of the important features of the connector as well as walking you through the technicalities of ingesting data into Salesforce Wave Analytics Cloud by leveraging features within Anypoint Platform.
Salesforce’s Wave Analytics Platform is a data discovery tool built to enable organizations to derive insights from their data. But when you take these scenarios into consideration, loading data into the Wave Analytics platform can seem to be a challenging task:
data trapped in on-premise databases or back office ERP systems
the need for data cleansing and data mashup from disparate sources
the need for event-based triggering or scheduling of uploads
With an event-driven architecture, built-in functionality for batch processing and out-of-the-box connectors that help you integrate with different data sources, you can do all of this and much more with Anypoint Platform and MuleSoft’s Salesforce Analytics Cloud Connector.
New Features
Ability to integrate with multiple Salesforce Analytics Cloud instances based on the login URL provided to the connector.
Support for the latest version (Summer ‘15, v34.0) of the Salesforce Analytics Cloud External Data API.
4 types of authentication mechanisms – Basic, OAuth 2.0, SAML Bearer Assertion and JWT Bearer Token Flow.
Support for operations such as Append, Delete, Overwrite and Upsert and fields such as NotificationSent, NotificationEmail and EdgemartContainer
This is the where you define the header to create a data set. Salesforce prescribes the use of a metadata.json file to define the header of the data set. The connector operation that does this for you is “Create Data Set”. In this step, you will have to enter the location of the metadata.json file as a part of the connector configuration.
Here, you get the ability to chose whether you want to Overwrite, Upsert, Append or Delete the data set. You also have the ability to enter in the Label, name of the Data Set and the Edgemart Container. You can set up an email notification and set the condition which determines when to send the email notification.
Now that you have created the data set, you need to load the data from your external data source into the Wave Analytics Platform. The “Upload external data” operation in the connector does this for you. As prescribed by the External data API documentation, the ingestion of data into the Analytics cloud happens in chunks of data that are smaller than 10MB. The connector caches the data it receives from the source till it reaches a file size of 10MB and then it flushes out the data to the Wave platform. When dealing with very large file sizes the most optimal solution in terms of performance is to proactively split your file into 10MB chunks before it reaches the connector.
Anypoint platform has got the perfect solution to facilitate this in Batch Processing. Now, it may be difficult to estimate how many records in a file makeup 10MB worth of data. To solve this problem the connector throws a warning when the Batch Commit size is greater 10MB. This is your signal to reduce the Batch Commit size (i.e. number of records) till the warning disappears during deployment. Alternatively, for smaller files, you can load the data without using the batch process.
After the Header has been created and the data has been loaded, use the “Start data processing” connector operation to create a dataflow job. Once the processing starts, you cannot edit any objects. If you have set an email notification, you will get an update notification once the data ingestion is over. You can also check to confirm if the data can be seen in the Wave Analytics UI.
Alternatively, you can combine the aforementioned three steps using a single connector operation “Upload external data into new data set and start processing”. This approach is useful when dealing with smaller files as the batch process is incompatible with this operation.
Keep in mind that as the connector leverages the External Data API in its implementation, theAPI limitations apply to the connector as well.
Stay updated with the latest features in Anypoint Platform by subscribing to the MuleSoft blogs. Until next time, ciao!
and a webinar about our powerful yet simple new transformation engine, DataWeave, we introduced you to Selector expressions so that you can navigate to and retrieve particular parts of the incoming message. We also showed you how to apply iterative and conditional logic as is required in almost all transformation scenarios.
We now present to you a use case which involves transformations from Java Lists to XML and from XML to JSON.
Scenario
Alainn Cosmetics are adopting an API-led connectivity approach in order to cater to their Innovation team’s demands to get digital solutions to market in a more rapid and agile fashion. They are now working on an initiative to get information about their products to their new Android and iPhone apps. The idea is to build a new Experience API which will deliver this information to the apps with JSON payloads. This same API will call down to a System API responsible for interacting with the system of record for the product information.
System API: From Java to XML
This API reutilizes some of the Messaging and Model schemas previously designed for their SOAP based web services. The abstraction around Item information hides completely any details about the underlying system of record, which in this case is a MySQL database. A GET call to https://alainn-item-api-v2.cloudhub.io/api/items should return an XML payload as follows:
Note how there are a number of <Item/> elements and each of these has a number of <Image/> elements. The <summary/> element is optional. The implementation of this API contains the logic to integrate with the MySQL database where the Items are stored. The SQL query sent to the database returns a Result Set which contains the entire set of data including the repeating image for each item.
So you can see the mismatch between the XML document which embeds the repeating Image information inside each Item and the ResultSet which Mule abstracts as a Java List of Maps (each entry on the Map is effectively the column name as defined in the SQL query and its value). The solution to our problem ought to include a grouping together of those Maps which belong to the same Item.
Grouping Logic
Let’s simplify the above so that we can visualize how our groupBy function will convert the DataWeave array of objects (a Java List of Maps is normalized as a DataWeave Array of Objects) into an object whose key:value pairs are determined by the criteria specified as the right-hand operand of the operator. Consider the following: we have as input an array of objects each of which has an item_id field. We will use the value of this field to act as our grouping criteria. Thus each unique value of item_id becomes a key on our output object, and the corresponding value is an array of those objects whose item_id values are equal to that same value.
Objects with Dynamically generated Key:Value Pairs
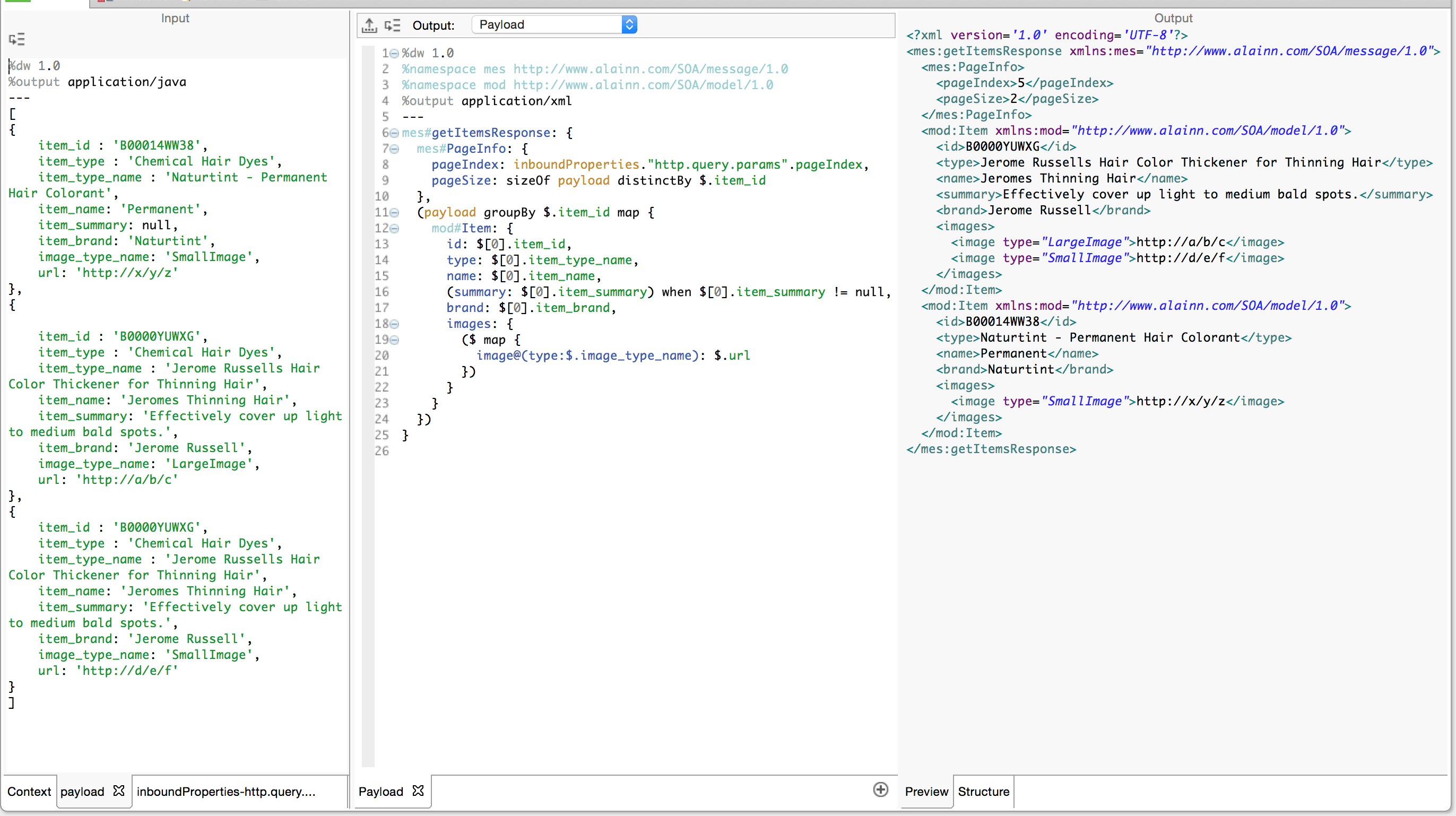
In our previous post, we explored the use of the map operator as a means to iterate through repeating content in our incoming payload. However, this represents a problem for us: the map operator necessarily produces an array, and we have already seen in the first Post that arrays cannot be rendered in XML. We want to iterate but we don’t want to produce an array. Rather we want to produce a new key:value (Item: {…}) pair inside our getItemsResponse object for each Item we encounter. Likewise, we want to produce a separate key:value pair (image: {…}) inside each Item object. We have seen that objects in DataWeave are defined as key:value pairs inside curly braces {}. In order to generate these key:value pairs dynamically, you need only wrap any expression which produces an array of objects in parentheses (). Our example above should suffice to see this. The payload is an array of objects. Let’s transform it to an object with a sequence of key:value pairs for every pair it encounters in each object in the array.
XML Namespaces
When faced with the need to navigate objects, the result of normalizing incoming XML or the need to render XML as the output of our transformation, namespaces will often need our attention. We use the %namespace <prefix> <uri> header directive to declare prefix – URI pairs. We then utilize these namespaces in our transformation with the syntax prefix#key. Typically, we don’t need to use them in selector expressions on the incoming data unless sibling keys in an object have different namespaces, and we need to distinguish between them.
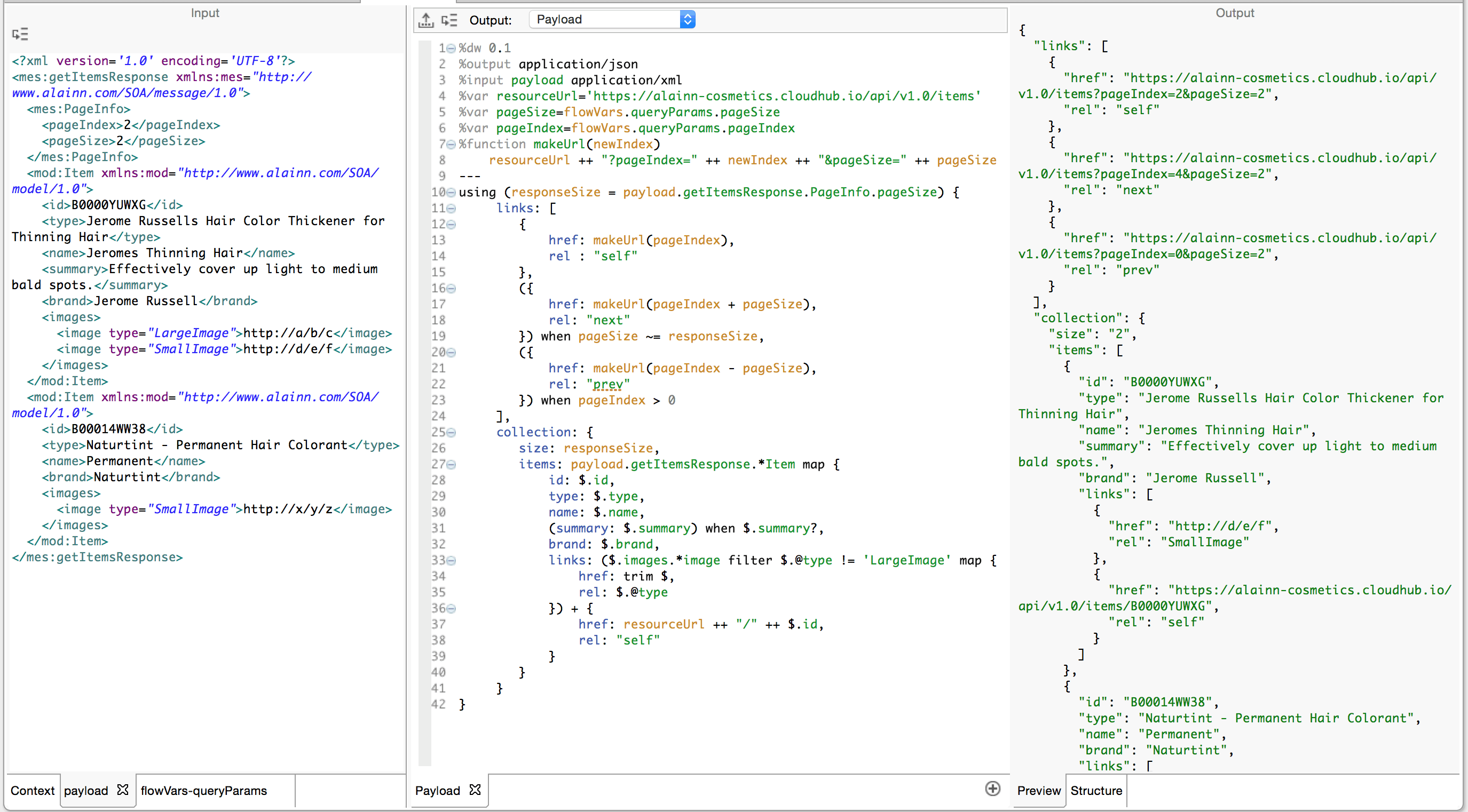
The Transformation
We now have enough tools to iterate through the array of objects (our result set) and build the corresponding XML.
Let’s summarize what we have learned in the light of the above expression:
Reserved Variables: We have immediate access to payload, inboundProperties, flowVars and sessionVars. These can be used at any point in the transformation.
De-duplication: To give a correct value for the pageSize key, we use the sizeOf operator. It looks at its right-hand operand and counts the elements (if it’s an array). We generated this array with the expression payload distinctBy $.item_id. The distinctBy operator iterates through payload and filters out any repetition of an object with the same item_id in the resulting array. Don’t forget that $ is an alias for the current iteration.
Grouping: Given that we should only generate one Item key: value pair for each unique item_id we encounter, it’s necessary to use the groupBy operator so as first to group the objects in the array. (Remember, a Java Result Set in Mule is represented as a List of Maps which in DataWeave is normalized as an array of objects.) The expression payload groupBy $.item_id produces an Object, where each key is the unique item_id we encountered in our Result Set, and its corresponding value is an array of the Objects which hold each record’s data.
Iteration: As we saw in part 1 of this series, the map operator always produces an array whose elements are produced by the expression in its right-hand operand. It iterates over the keys in the object given by our groupBy operator. Note how we use $ as a place holder for the current iteration in two different contexts as we build the images array. The outer $ refers to the current iteration as we iterate through the key:value pairs in the payload groupBy $.item_id map { } expression. The inner $ refer to the current iteration on the array as we map through the array of Objects for this Item.
Conditional Logic: Also covered in part 1, we use the when operator here to output the optional key:value pair for summary.
Dynamic Key:Value Pair Generation: Note how we surround in parentheses the entire payload groupBy expression as well as the expression we use to generate the repeating images. When we define the key:value pairs in an object expression, it is easy when these are static. However, if we need to generate them dynamically (we don’t know how many Items and Images we have in our Result Set) then we need to use the ( ) to extract each key:value pair from each object in the enclosed expression and add these to this object.
Namespaces: Note how we utilize prefixes to assign namespaces to the keys. mes#getItemsResponse and mod#Item are rendered each with the namespaces which correspond to the prefix we defined in the header.
Experience API: From XML to JSON
This API is exposed for consumption by an Angular App and an iPhone and Android App. The API delivers a JSON payload which contains some hypermedia links. A GET call to https://alainn-my-special-offers-api-v1.cloudhub.io/api/offers should return:
Functions
We can declare functions that are reusable throughout the entire transformation using the %function <function-name><function-body>header. We make reference to them by name, passing in actual values to the formal parameters declared in the function signature. The body of the function declaration is an expression of any type and will be evaluated with actual values for the parameters for each invocation.
Global Variables
Using the %var <variable-name>=<initial-value> global variable declaration we declare variables which can be used in function bodies as well as the entire transformation expression.
Type Agnostic Comparison
Whenever we make numeric comparisons we need to be mindful of the fact that incoming XML values are usually normalized as strings and that strings are never equal to numeric values. Hence, the string “3” is never equal to the number 3. There are two ways we can address this problem. Either we use the as :<type>type-cast operator or we use the ~= operator. This will cast both operands to the same type and guarantee that “3” ~= 3 will always return true.
Key Presence Conditional Logic
We have seen how we can apply conditional logic to test for value comparisons. Sometimes, we just need to test for the presence of keys in our objects (remember that XML elements are often optional according to their schema definitions). We do this with the .<key-name>? operator. This will return true if the key is present on the context and false if it is absent.
The Transformation
Let’s apply all of the above in our final expression:
Consider the following areas of logic which we utilized in the transformation:
Function calls: We declare makeUrl(newIndex) to build URLs with the value of newIndex for our hypermedia links.
Conditional Logic:
The generation of the prev and next hypermedia links is optional. Note the use of the type agnostic comparison for pageSize ~= responseSize.
We only generate a summary key for each item if we find a summary key on the input. We do this with when $.summary?
Array Operators: We append elements to arrays with the + operator. In this case, we append the self hypermedia link.
Variable References: Note the use of global variables defined in the header. These are referenced by name throughout the expression. Note also the use of local variable declaration prepended to the object expression with the using() clause. Remember the scope of local variables is limited to the expression to which the clause is prepended.
Namespaces:Though the input XML document contains namespaces, we don’t actually have to reference these in our key selector expressions unless there are sibling keys with the same name and different namespaces. Namespace aware key selectors take the form .<prefix>#<key-name>. In this case we might say payload.mes#getItemsResponse (depending on a namespace declaration in the header) but because all the keys are in the same namespace there is no need.
Summary
That’s it! You can download the APIs built for these two use cases here:
In our next post, Getting Started with DataWeave: Part 4, we will give you a cookbook style guide to some rather interesting and complex transformations. And if you haven’t already, make sure to watch our DataWeave webinar.
This all began with a very popular request: “We want to be able to throw an Exception from a flow”. The motivation for this is that it’s fairly common to run into “business errors” (errors not related to the handling and transmission of data but the data itself) which should actually be treated in the same way as a connection or system error (things like the remote endpoint is down).
Given the popularity of the request we decided to look into it and started by asking: “which are the use cases in which you would throw an exception?”. 100% of the answers were: “because the data was not valid after applying some X criteria”. So, instead of doing a very raw <throw-exception /> message processor we decided to build a validations module, which throws exceptions when a validation fails.
Do we really need this?
It’s a very common use case when doing integrations to need a mechanism to test some conditions are met and throw an exception if validation failed. Mule currently provides some mechanisms that can be used for validations but none of them completely fulfils the use case:
Filters
Filters can stop execution of a flow if a condition is not met, however they’re not a good fit for this because:
Filters are conceptually conceived to just kill event’s processing. They can throw exceptions, but you cannot customise the exception type. So if you have two filters in the same flow you cannot know which one failed. They don’t throw an exception or provide any mechanism to take action on that error.
Filters often require you to write a MEL expression for each validation. Not an out of the box solution.
At the end of the day, reality if that even though filters can sometimes be used as validators, they’re not conceived for that.
Choice + scripting component
Another option is to use a choice element to evaluate the condition and then throw an exception using groovy or other expression evaluator. This solution is quite verbose and overly complex.
You have to evaluate the condition through a custom expression
You need custom code to actually throw the exception
The choice element forces you to an unnecessary <otherwise> clause
Availability
This feature is available starting with Mule ESB 3.7.0, in both Community and Enterprise editions. However, Studio support only became available starting with the September 2015 release.
Validation Basics
The validations module was designed under the following principles:
If validation fails, a ValidationException will be thrown.
By default, this exception will have a meaningful message attached. You can optionally customize this message and change the type of exception thrown, as long as the new exception type has a constructor that overrides Exception(String).
For cases in which you want to throw an Exception without such a constructor, or which creation is not trivial, or which is to contain additional information, there will be a factory interface you can implement to create that exception
Ways of accessing a validator
In most cases, there’re two ways of using a validator: through a MessageProcessor or through a MEL function.
Through a MessageProcessor
We provide a message processor for each of the validators. This is what you use when you want to perform the validations as part of your flow and you want an exception to be thrown if a validation fails.
If you like to build your flows using the visual designer in Anypoint Studio, then the validators are exposed as a single item in the components palette:
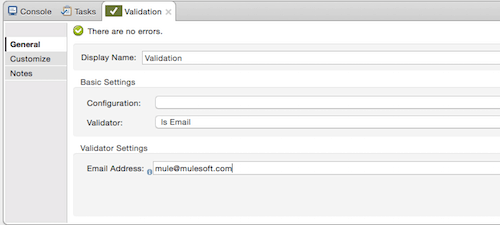
You can then select the validation type:
The parameters of the validator you selected are then shown:
If you prefer to get your hands dirty and write the XML manually, then each validator is a different message processor in the validation namespace:
A nice thing about the message processors, is that they all accept expressions in all their parameters.
Through MEL
The purpose of exposing validators through MEL is to use them in decision making. Unlike the message processor version, these will be boolean functions without an output message, just true if the validation succeeded, or false otherwise. All the validators are available through a validator variable automatically added into the MEL context.
Validate Email address
Checks that a given email is valid.
From XML:
It can also be used through MEL:
Validate using a regular expression
Validates that a given expression matches a Java regular expression.
The caseSensitive parameter is optional and defaults to true.
It can also be used through MEL:
Validate a string is a valid time according to a pattern
Pattern and locale are optional arguments.
Locale defaults to the system’s locale
Pattern defaults to the locale’s default pattern.
This same validator can also be used to process a timeless date:
Also available through MEL in various overloaded forms:
Validate String, Collection or Map is not empty
In the case of a String, the definition of not empty is that length is greater than zero and it’s not all whitespace characters. In the case of a Collection or Map, it refers to how many items are contained.
Also available through MEL:
Validate String, Collection or Map is empty
The exact opposite of the not empty validator
Validate size
Validates that the input’s size is between a min and max boundaries. This is valid for inputs of type String, Collection, Map and arrays (in the case of the String, the size is actually its length).
min is optional and defaults to zero, which in practice means that a blank String is accepted. This number must be in the integer range
max is also optional and defaults to null, which in practice means that no upper bound is enforced. This number must be in the integer range
Also available through MEL:
Validate not null
Fails if value is null or an instance of NullPayload
Also available through MEL:
Validate null
Fails if value is not null and not an instance of NullPayload
Also available through MEL:
Validate a String can be transformed to a number
The processors above validates that a String can be parsed as a number of a certain type. minValue and maxValue are optional and allow to check that, if valid, the parsed number is between certain inclusive boundaries. If not provided, then those bounds are not applied.
The valid options for the numberType attribute are:
INTEGER
LONG
DOUBLE
SHORT
FLOAT
It is also possible to specify a pattern and a locale to perform the validation.
Locale defaults to the system locale.
Pattern defaults to the locale’s default pattern.
Full form of this validator would be:
Also available through MEL:
Validate IP address
Checks that a given ip address is valid. It supports both IPV4 and IPV6. In the case of IPV6, both full and collapsed addresses are supported, but addresses containing ports are not.
Also available through MEL: #[validator.validateIp(‘127.0.0.1’)]
Validate url
Validates that a given String can be interpreted as an url. This is done by invoking the URL(String) constructor in the java.net.URL class. If that constructor throws exception then the validation fails. Whatever String which that constructor accepts is considered valid.
Also available through MEL with two overloads:
Boolean / Fallback validations
Although the validations above are quite general and cover many use cases, there’s always the possibility that it doesn’t quite matches your use case, that’s why there’re two fallback expressions which simply evaluate that a given expression is true or false:
Notice that:
Because conceptually speaking a validator should not modify the message payload or any of its properties, the MEL expression used here is expected to not have any side effects.
It makes no sense to expose these through MEL since boolean comparison is something already built into the language.
Custom Validators
If you want to perform complex validation logic, or reuse some code you already have on a separata jar, then the is-true and is-false fallbacks might not be that convenient. You might want to build your own validator.
Leveraging the Validator API, users can create their own validators, and there will be two mechanisms to execute them in a flow. Next we’ll list the steps necessary to do that
Implement the Validator interface
Just like other components like the MessageProcessor, Filter, Router, etc., the validators also have a well defined contract inside Mule’s code:
And in case you’re wondering, here’s how the ValidationResult looks like:
Your implementations of the Validator interface are required to:
Have a default constructor
Be thread-safe
Should not have any side effects over the message payload or any of its variables
Once you’ve done that, you can execute the validator through the custom-validator message processor:
Each instance of custom-validator will create its own instance of the given class and will hold it, thus the requirement to be thread-safe. The recommended way of achieving thread safeness is by being stateless, but that’s up to the developer.
Another option is to reference the custom validator via a registry name:
Notice that once more, the instance of the validator to be used will always be the same across different executions and thus the validator needs to be thread-safe. Your implementation of Validator can be either in the project or in a jar you add to the classpath. It doesn’t matter as long as it’s instantiable by the application’s class loader
Customizing exception class and message
There’re some cases in which the user might require low level control on how exceptions are created when a validation fails. For that, the following interface will be used:
This interface receives the Event which failed the validation and the validator that raised the error. This method is intended to return the exception to be thrown but not to throw it.
Implementations of this interface should never throw exceptions and be thread-safe and have a public default constructor.
Global Level
At a global level, you can only override the default ExceptionFactory. It doesn’t make sense to try to customize a message at this point since you don’t know which validator might fail. You can configure it like this:
You could also provide a reference to a Spring Bean instead:
Notice that you either provide a classname or a bean reference. You can’t do both things.
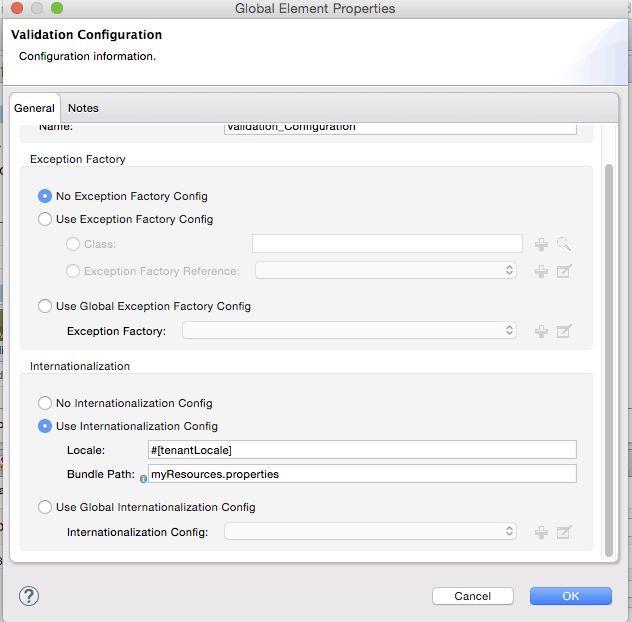
In Studio, you can do the same by creating a validation:config global element. You can do that by dropping a validation component in your flow and clicking on the add configuration icon:
Then select the validation configuration:
You can either provide the classname of an ExceptionFactory or a reference to a Spring Bean.
Validator Level
On any of these validators you can customize the type of exception thrown by providing the canonical name of an exception type. If that exception type does not override the constructor Exception(String) an IllegalArgumentException will be thrown. You also get the chance to customize the message of the exception thrown.
The above setting overrides the global ExceptionFactory configured in the validation config and creates the exception by those parameter. NotAnAdultException is expected to have a constructor taking one String argument, otherwise it will fail (that will be validated at start time).
NOTE: You don’t have to customize both the exception type and the message, you can also just customize one of them.
In Studio, you can do this clicking on the customize tab that you get on every validator component:
I18N
Since validators provide a message upon failure, another common concern is how to apply I18N. By default, the common validators provide their message in American English. Those message are not hardcoded but in a resource file. Users wanting to provide their own internationalized messages can do so by specifying their own resources file at a config level:
The i18n is optional, but if you specify it then the bundle Path attribute is mandatory. The locale attribute is optional and defaults to the system locale. However, it is most useful when used with an expression which returns the locale to be applied on the given event:
The example above assumes that by the time the validator is executed, there will be a flowVar called tenantLocale in which the locale to be used has been set (local is optional, it will default to the current locale).
You can also do this in Studio using the global elements config dialog, just like with the ExceptionFactory:
Validating many conditions at once
There’re scenarios in which you want to evaluate many conditions with the possibility that many of them fail. In those cases, it’s useful to generate only one error with all of the descriptions. This use case is also supported:
About the all validator:
All validations are executed, even if all of them fail
If any of the validations above fail, one single exception will be thrown. The exception contains a multiline message in which each line corresponds to each failing validation.
Validators are executed sequentially using the flow’s thread
Since validators don’t have side effects, the order shouldn’t matter
Unlike the other validators, the all validator does not allow directly customizing the exception type or the message through a validation:exception or exception factory elements (you can however customize the message of the inner validators though).
In Studio, you can use this by dropping a validation component into your flow and choosing the “All” validator. You’ll get a table below in which you can add/edit/remove your custom validators:
Example: Validate json Http Post
Let’s wrap this up with a simple example. Suppose that someone is posting the following json through a http listener:
Now consider the following config:
In the example above we validate that:
First and last name are not empty strings
That the age is a valid integer number above 18
That the email address is valid
That the social security number has the correct size and matches a regular expression
Valid feature?
That’s it. We hope you like this feature. Have feedback? Please comment!
In order to connect assets to audiences with speed and scale, you need a powerful data transformation tool. That tool should be able to integrate in real time using APIs, do batch tasks such as data ingestion or synchronization and handle a variety of data sources – from JSON to EDI to XML.
Our solution is called DataWeave. It’s a simple, powerful way to query and transform all types of data. If you’re interested in getting started with DataWeave, MuleSoft Principal Solutions Consultant Nial Darbey has written a series of blogposts designed to help you get going.
If you’d like to see a demo of DataWeave, Nial and MuleSoft’s Director of Product Management, Dan Diephouse, will be showcasing DataWeave’s capabilities on September 30, 2015, at 10 AM PST.
In the Getting Started with DataWeave: Part 1, we introduced you to DataWeave and its canonical format, the result of every expression you execute in the language. We now continue to explore our new transformation engine, aiming to give you enough grounding to tackle real-world use-cases.
As we did in Part 1, we will continue to show the results of each expression in the DataWeave canonical format.
Your entire transformation is encapsulated in a single expression. In Part 1, we discussed writing semi-literal expressions to define the outer structure of your transformation as either an object or an array. Inside this expression, you can write other expressions of different types. There are 7 basic expression types in DataWeave:
Literal
Variable reference
Semi-literal
Selector
Function call
Flow Invocation
Compound
We covered literal, semi-literal and variable reference expressions in Part 1. In this post, we concentrate on Selector Expressions and Compound Expressions and refer you to our documentation for a complete coverage of these and every other expression types.
Selector Expressions
Selector Expressions are necessary for just about every transformation. They allow us to navigate to any part of the incoming data whether it be in the payload, variables or properties. You should bear in mind two things when utilizing selector expressions: their context and their result. They can be appended to each other to form a chain of selectors. The result of each selector in the chain sets the context (object or array) against which the next selector is evaluated. The first context will typically be the result of a variable reference expression, payload for example. However, any expression can set the proper context. Selectors only make sense when applied to objects or arrays, so you simply need to ensure that the context you set is an object or an array. Invoking a selector expression on a simple type will always result in null. (Strings are the exception to this. They are treated as arrays.)
Array Element Selector Expressions
Arrays, as you would expect, are indexable with the usual [0..n-1] notation. We also allow selection of ranges within the array. For your convenience, the indices can be negative, where -1 indicates the last element on the array. The range beginning with the second element and ending with the last element on array x would be indexed x[1..-1]. To retrieve the third last element to the first in reverse order you need to write x[-3..0].
Object Selector Expressions
Single Key Selector
We have seen that DataWeave objects are sequences of key:value pairs in which the keys can be repeated. Many use cases will require you to retrieve particular values from deep within the object. To do this you will need to use the key selector, written in the form .<key-name>. The result is the value corresponding to the first instance of the key you specified.
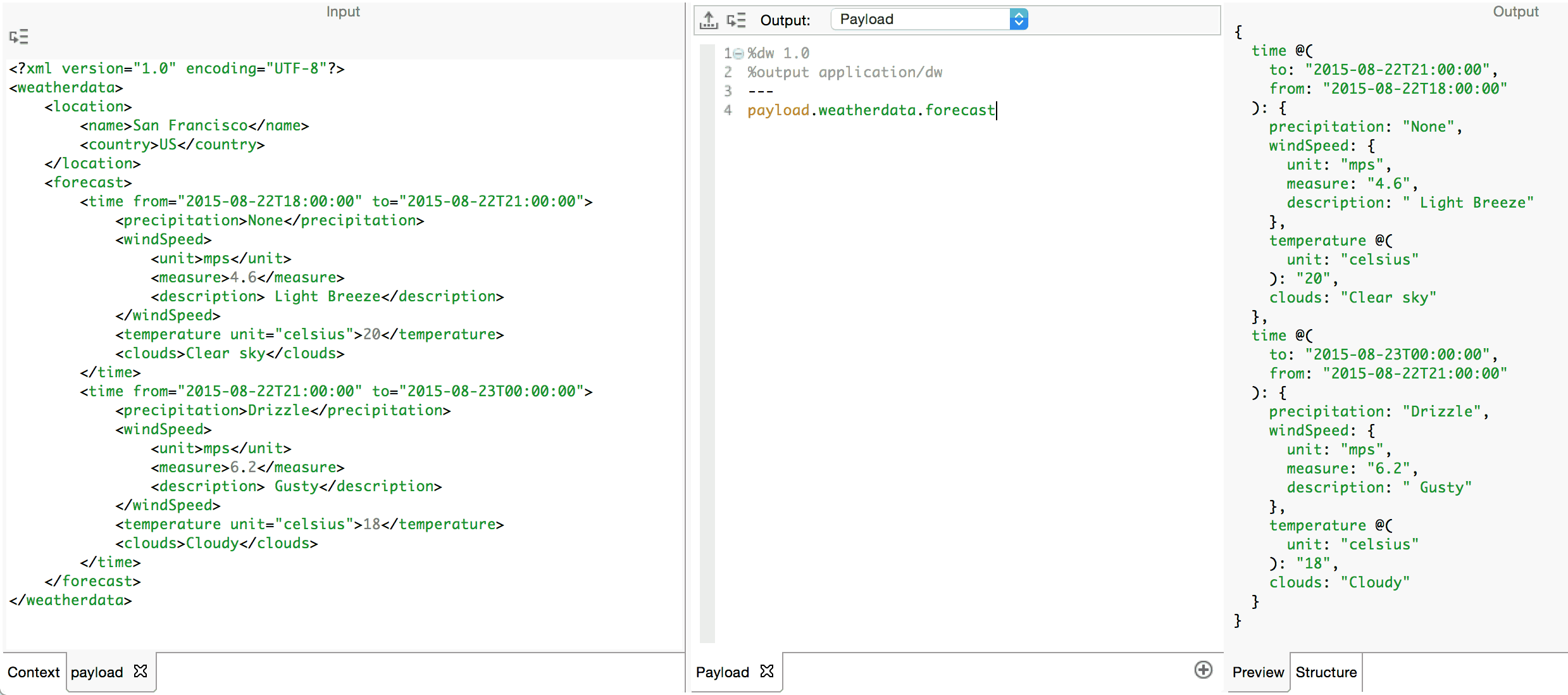
Let’s take a look at our weather data XML document again and extract just the contents of the forecast and excluding the location. Bear in mind what we learned about variable references. The payload expression normalizes the input XML document into a DataWeave object whose key:value pairs correspond to the elements and their respective contents.
Note how we can chain the selectors together to navigate to the key of interest, in this case, forecast. See how the result is the value corresponding to that key. Hence, the forecast key does not appear in the result of the expression. Consider the following table of the results of navigating further into the object with payload.weatherdata.forecast as the initial context.
Multi-key Selector
Note how the .time selector results in the value of the first instance of time in the initial context object. However, what if we wanted both values? To retrieve the value for each repeating key, you must use the multi-key .*<key-name> expression. This will always result in an array of the values, even if there were only one instance of the key. Hence, the expression payload.weatherdata.forecast.*time will result in an array containing the values for each time key instance in the order in which they appear in the context object.
An important point to make here: when the context of your key selector expression is an array of objects, both the single-key and multi-key selectors will iterate and apply against each object in the array and the result is always an array. Consider the following table of expressions where we again use payload.weatherdata.forecast as the initial context:
Attribute Selector
You may have noticed that the attributes present on the time keys did not appear in the results of any of the above expressions. The key selector expressions only return the value corresponding to the key. When you need to retrieve a particular attribute, you should use the .@<attribute-name>attribute selector. Hence, the value of the from attribute on the first time instance above is retrieved with payload.weatherdata.forecast.time.@from. DataWeave provides a handy shortcut to get all the attributes as an object of key:value pairs. payload.weatherdata.forecast.time.@ will return both the from and to attributes wrapped in an object:
Compound Expressions
Thus far you have seen some of the basic building blocks you will use in a DataWeave transformation. You will enjoy the real power of the language when you combine these expressions together using operators. We explore some of the most important of these next.
Iteration
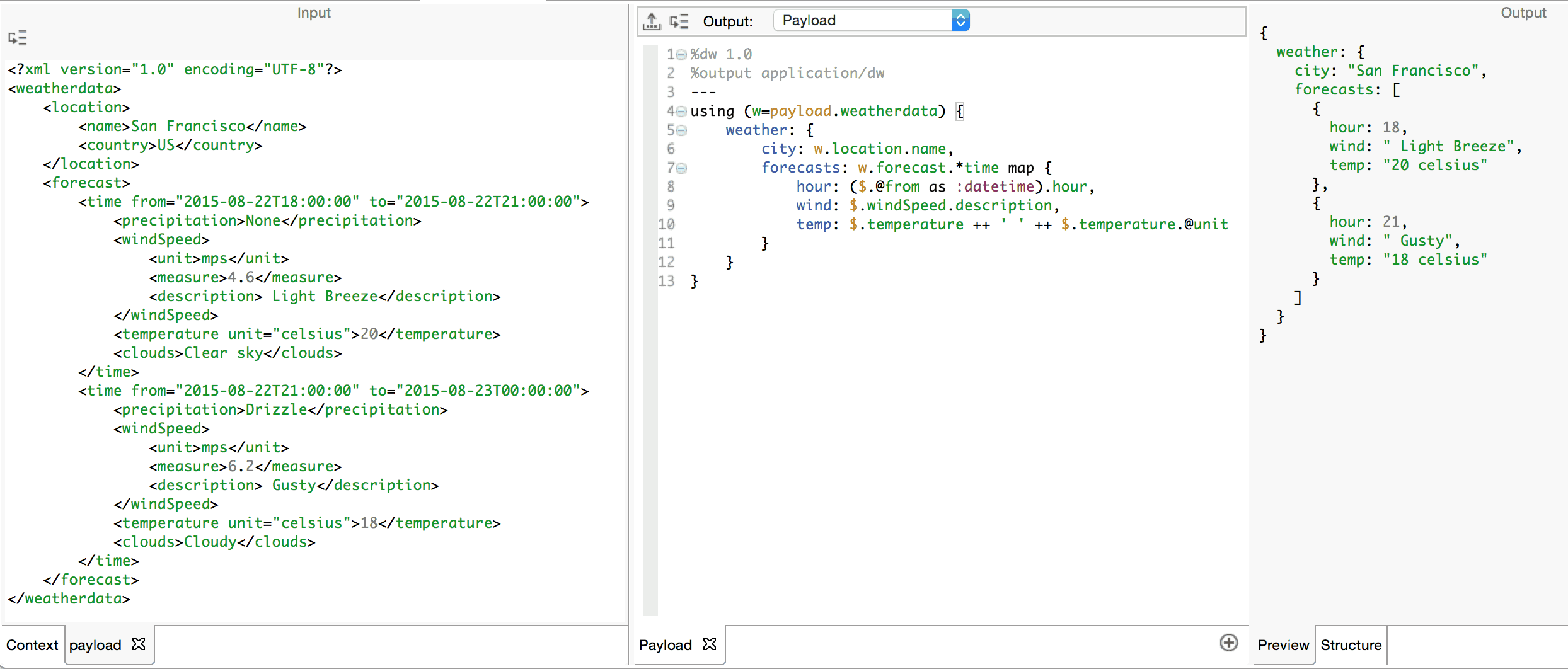
Let’s continue to work on our example weather forecast XML document and transform it so that we get some basic information from it. We are interested in the hour for each of the forecasts and a human readable summary of the wind and the temperature. Of course, there are many forecasts for the day, and we need to iterate through each one. We use the map operator for iteration. It takes as operands an expression which must return an array or an object on the left-hand side and any expression on the right. The result of applying map is an array where each element is the result of the right-hand operand. If the left-hand operand is an array, map will iterate through each element and add the result of the right-hand operand to the output array. If the left-hand operand is an object, map will iterate on the sequence of key:value pairs. Let’s say we wish to build a forecasts array containing objects with 3 fields: hour for the time of the forecast, wind for a description of the wind conditions and temp for a description of the temperature.
A couple of things to note here:
Using (w=payload.weatherdata) is a local variable declaration prepended to the object expression which defines our entire transformation. This variable, w, is considered local to the object expression to which the declaration is prepended. Hence, it is only valid to reference w within the scope of this object.
Map will iterate on each element in the array returned by .*time and add the object defined as its right operand to the resulting array.
$ is an alias for the element found at each iteration on the array.
$.@from is the selector expression used to access the value of the from attribute.
as :datetime is a type-cast expression. The .hour expression can thus be used to extract the hour from the date and time.
For simple string concatenation, we use the ++ operator.
Filtering on Iteration
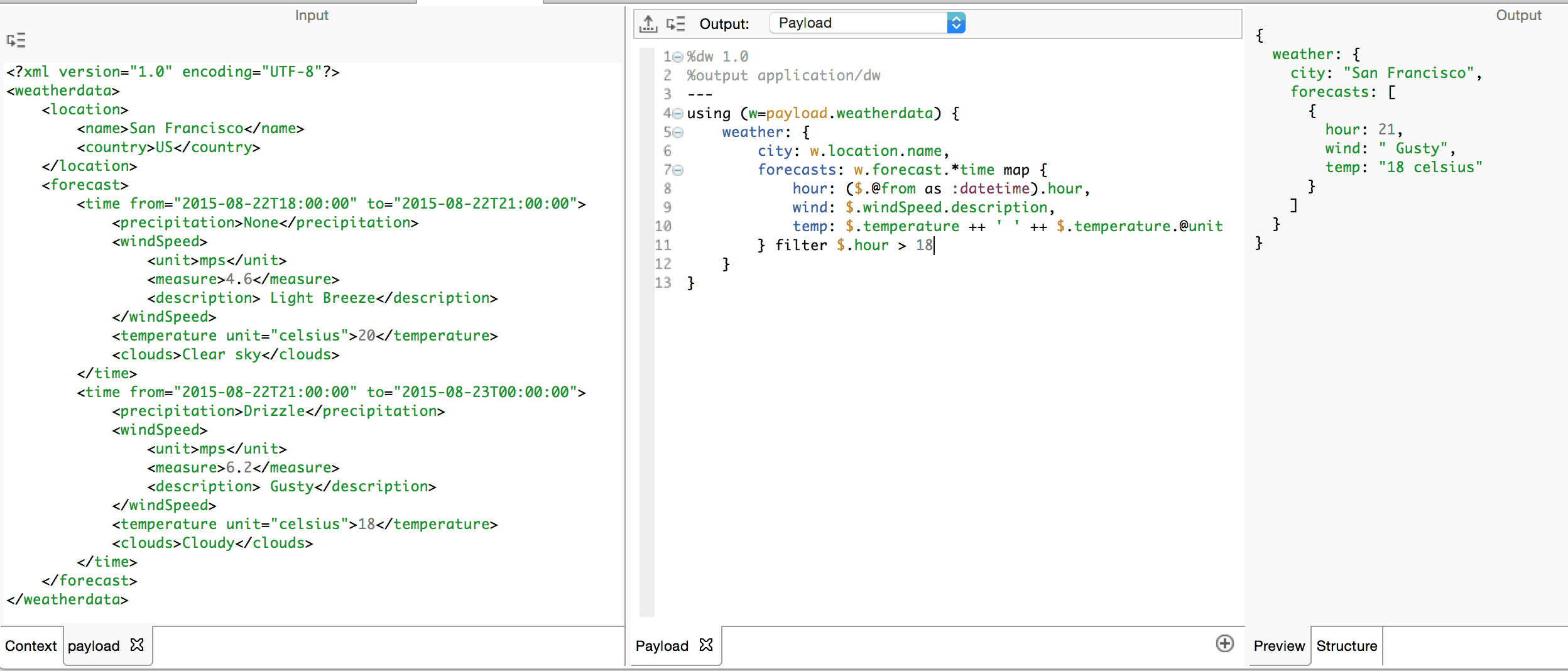
We are free to chain expressions together as compound expressions with any number of operators. Often we need to filter the data we work against before or after the operator of choice. The filter operator iterates through elements in an array or keys in an object and produces an array which contains only those elements which match the criteria specified by its right-hand boolean operand. Let’s say we want to filter the array produced by map above so that we only get those forecasts after six o’clock pm:
Note how the criteria expressed in the right-hand operand makes reference to $.hour. This key was not present in the original input. It is important to be mindful of the results of each expression in the chain of expressions that form a compound expression. The first expression which utilizes the map operator produces an array of objects with hour, wind and temp keys. This array becomes the left-hand operand of the filter operator, which iterates through the array and produces an array of objects filtering out those objects which fail the said criteria.
Conditional Logic
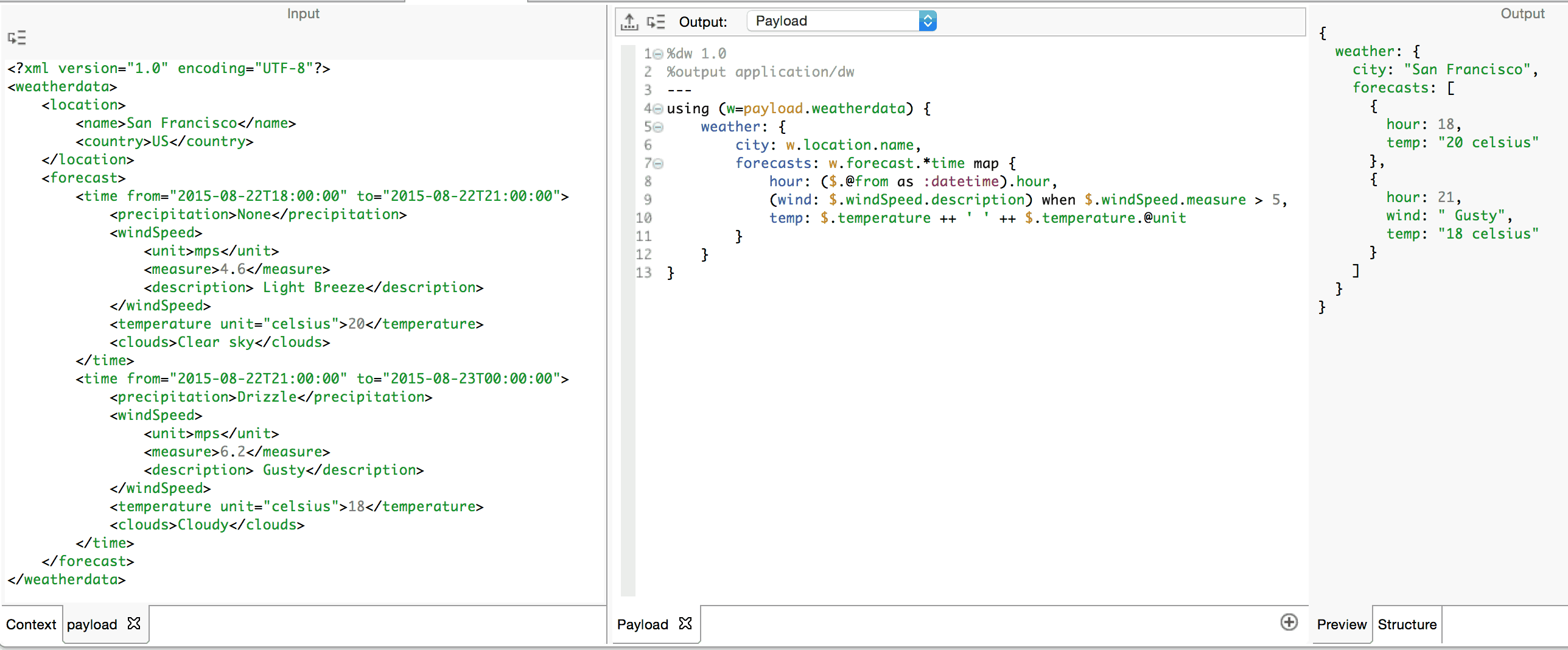
Often our transformation logic needs to output data only when we meet certain criteria. Let’s output every forecast but only include the wind description if the speed is greater than five miles per hour.
Note how we surround the entire wind key:value pair in parentheses. This is the left-hand operand to the when operator. The right-hand operand is a boolean expression. Only when this evaluates to true, is the wind key:value pair included in the output.
Next Steps
That’s it! You’ve just mastered the essentials to utilize DataWeave in every transformation requirement from simple to complex. In our next post, Getting Started with DataWeave: Part 3, we’ll guide you through a real-world scenario of transforming between Java Database result sets, XML and JSON payloads as you expose data through System and Experience APIs.
Also, you can now view our webinar on demand that introduces Dataweave.
We are very happy today to unveil today not one, but two major updates across the MuleSoft developer experience: 1.) our brand new documentation platform, and 2.) a totally revamped developer forum.
A brand new doc platform
You can have the greatest technology in the world, but it means nothing if you don’t have fast, intuitive, and eminently searchable documentation by its side. When you couple those two things together, you get something that’s way better than the sum of its parts, a force to be reckoned with, much like Jay-Z and Beyoncé. And as they eloquently put it in their celebrated 2007 duet, when it came to documentation we felt it was time to upgrade you.
Here’s a preview of what you’ll find with our new docs:
Speed: Need answers now? Each page is static, so they load faster than it took to read this sentence.
Search: Looking for something specific across thousands of topics? Search has been integrated into every page, providing you with immediate suggestions and curated results that will continually improve.
Community contributions: With our built-in GitHub integration, we’ve made it a cinch for you to add or suggest changes, directly within our docs. Simply click “Edit on GitHub” on any topic to make a contribution.
Custom platform: In rebuilding our docs, we did look at many vendors, but decided to eschew them in favor of building something entirely novel on GitHub and the open source Asciidoctor format. The result: beautifully rendered docs that load incredibly fast.
For more information on our new docs and why they rock, stay tuned for a deep dive from our documentation team. In the meantime, visit http://docs.mulesoft.com.
A re-engineered forum
In the same vein, we’re stoked to present you with a completely redesigned forum. Built on AnswerHub, and completely re-designed from the ground-up by our team, we tried to make it easier than ever for you to find the information you want, collaborate with others, and share your knowledge.
New UI with improved search: Finding topics, asking questions and finding pertinent answers has never been easier
Shared Content: You can now share your content (blog posts, slide decks, videos) with the rest of the community.
Karma & Gamification points: The more you engage and share helpful answers, the higher your reputation within the community.
Integration with the Champions Program: If you’re a MuleSoft Champion program member your activity and yes, your badges, will be visible alongside your profile.
We hope you enjoy kicking the tires on both of these new tools and would love to get your feedback and/or questions at developers@mulesoft.com. Between these two releases and our brand new blog and developer website updates earlier this summer, we look forward to blazing new trails with you.
Dreamforce is around the corner, and we’re happy to announce that our developer team will be returning to the Dev Zone next week.
On tap:
-Our “can’t miss” Dev Zone Theatre session: “Build a Connected App in 10 Minutes or less with Lightning and Data Gateway”. In this short session, you’ll see how Lightning Connect, coupled with MuleSoft’s Data Gateway lets you simply connect Salesforce to all the data you have in your peripheral systems.
-Our Dev Zone Booth: Join our team of MuleSoft experts at our booth, stationed on the far left side of the Dev Zone between the Salesforce University stand and the Trailhead Basecamp. Our team will be at the ready to walk you through demos of some of our most popular integration use cases: order to cash processes (between Sales Cloud and SAP), HR engagement (using Force.com and Workday) and how to offer transformative experiences for healthcare organizations with our HL7 connector and Salesforce.
Here are the days and times where you’ll be able to find us:
September 15 – 8am-8pm
September 16 – 8am-6pm
September 17 – 8am-6pm
September 18 – 8am-2pm
So get ready for four days of connectivity, and we hope to see you there! And if you’re looking for real-time updates, follow us on Twitter at @MuleDev.
Don’t forget to register here using the promo-code EC15MLFT to receive $100 off a full conference pass, and don’t forget to use the MuleSoft Dreamforce 2015 landing page to make sure you can find us on-site.
You have been redirected
You have been redirected to this page because Servicetrace has been acquired by MuleSoft. Click here to learn more.







































{kind=link}